Integration with external SQL data sources
Introduction
The document describes the mechanism of importing data into the system from external data sources such as SQL servers (Relational databases). Using the integration mechanisms built into the system, we can flexibly define data and system behavior for data import. Data is imported to the parameters of selected resources or directly to production data in the case of using production management systems.
| The AMAGE PVD (Edge Computing) application also has the ability to integrate with external systems via SQL exchange tables. An appropriate implementation model should be selected if such demand and availability of communication channels arise. The PVD application can be run on devices or servers in a location with direct access to integrated SQL servers. |
Task
We want to import data from an external IT system. This data is passed on to us via an exchange table. Data is periodically entered there by an external IT system and our task is to download this data, process it into the parameters of our resources and then delete the records we have already used from this table.
The database is test_db. The data table is test_table. The columns to be imported into one parameter are v1 containing the data and v2 containing the timestamp of registration of this parameter. All this must go into the history of the ThermalTransmittance parameter for device/resource SZ2. After completing the operation, the read records should be deleted.
| Using the definition of this ending, we can implement several different scenarios. This tutorial focuses only on this task. |
Import tip definition
To perform such data import/export, we can use the integration modules available in the system. We access them through the configuration section and the 'Data exchange' menu.
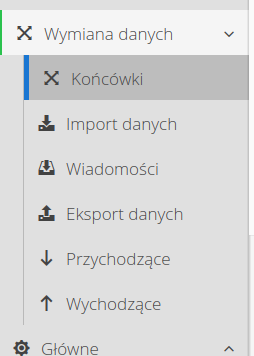
In the menu, select the Tips action. Using it, we will be able to define a new data terminal from which we will download data to the system. We define a new ending. This is the end with incoming data (we will download data to the AMAGE system) and the channel type is SQL.
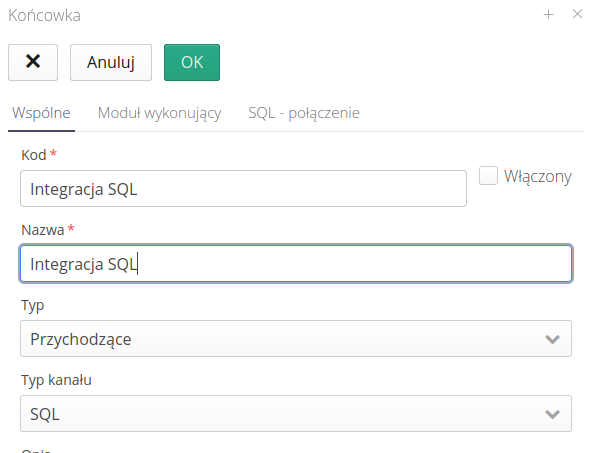
Using the next tab, we define basic information regarding data access. We select the server, user, database and data refresh/operation period.
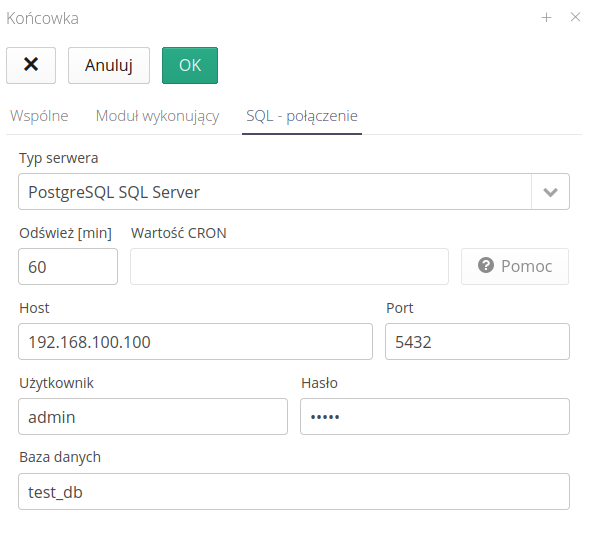
We go to the tab regarding the module performing operations. It is an automaton that will perform the operations we need based on a defined data source. We select the action SQL - parameters/production data.
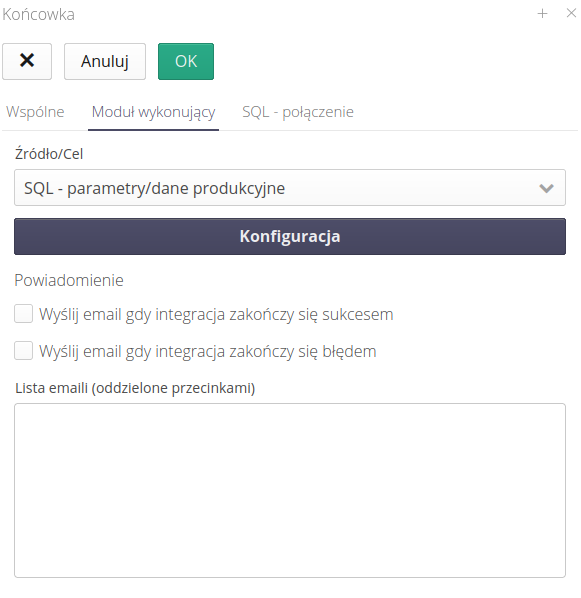
Definition of SQL queries
We proceed to editing this automaton performing operations. It consists of two tabs with data definition. The first one describes the SQL queries necessary to retrieve data from an external table. Here we can use any SQL queries that will be executed on the target table.
Additionally, we can define a final operation that will be performed after the data download operation is completed.
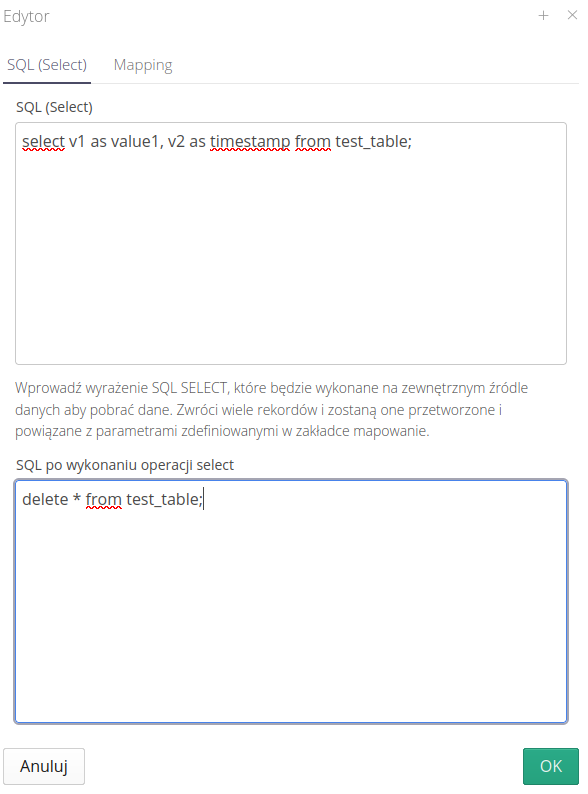
| SQL queries are executed in one transaction, for which data separation applies. Operations will only be performed on records that are available in this transaction. |
Parameter mapping
Then we go to the second tab. Here we can determine where the data we read using SQL queries will go to the system. We can define any number of such mappings. After creating a new mapping, the definition window appears.
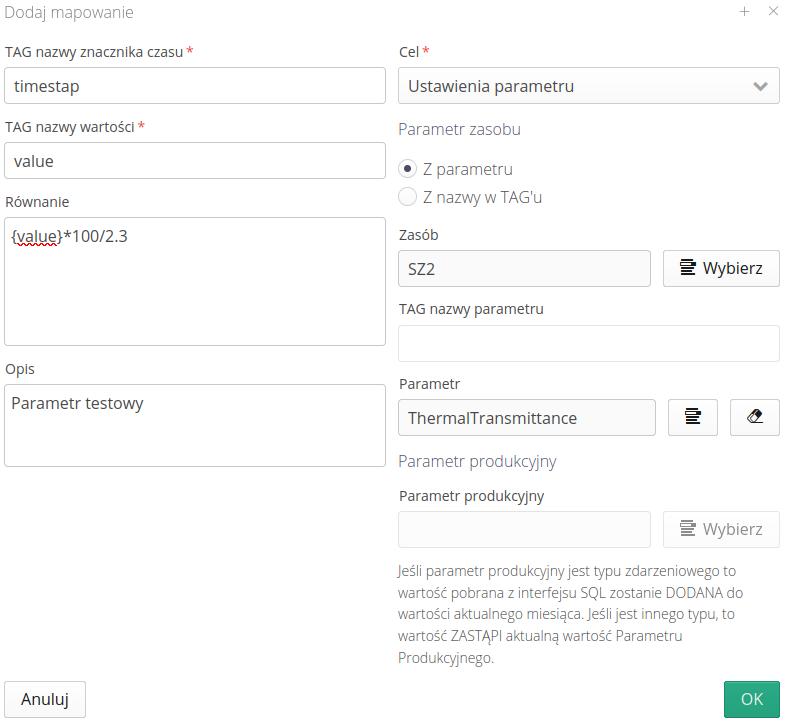
Using this window, we can define data and associate it with parameters in the system.
-
Timestamp name TAG - the name of the column in the SQL query that corresponds to the timestamp (when a given event was recorded)
-
value name TAG - the name of the column that contains the value to save (measurement, text, etc.)
-
Equation - using an additional equation and using the
{value}tag, we can define a rule that will convert a given parameter to the data we need, e.g. convert the value from kWh to MWh. -
Description - additional description for users editing these parameters
-
Purpose (parameter setting/production data) - defining which element the read record should go to. We can select either a parameter in the resource or production data. Depending on the selected option, the remaining parameters in this column are active or not.
-
Resource parameter - from the parameter/from the name in the TAG - we can determine whether the parameter name is set permanently, e.g. 'XXX', or whether we have a specific parameter that we want to read in the read data column.
-
Resource - a resource to which we will save the read values from the exchange table
-
TAG from the parameter name - if we have enabled parameter determination based on data from an external system, here we enter the name of the column that defines this parameter name
-
Parameter - if we have explicitly selected one parameter, we select it here from a previously specified resource.
-
Production parameter - if we have chosen to record a production parameter, we define its name here.
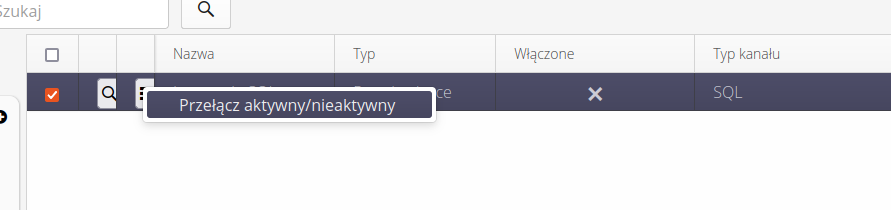
After editing, we can also use the context menu to change the status of the tip from active/inactive.
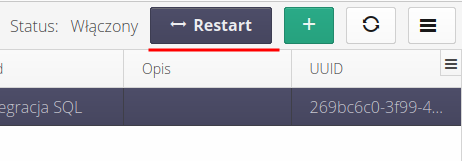
After editing the integration pin, remember to tell the system to restart the pins and load the configuration saved here. We do this using the Restart button in the upper right corner of the view.
Monitoring the operation of machines
We can view the operation of machines and all information regarding performed tasks in the log viewer, also available in the configuration section.
Ready ! Data is configured and transferred between systems.
| This Howto is based on system version 1.21.0.0 (03.2023) and presents features that may not be available on your system. Ask AMAGE to provide this functionality. |
| Due to ongoing development of the system, some screens or configuration files may look slightly different, but will still retain the full functionality described here. This does not affect the core functionality described in this document. |