Integracja z zewnętrznymi źródłami danych SQL
Wstęp
Dokument opisuje mechanizm importu danych do systemu z zewnętrznych źródeł danych typu serwery SQL (Relacyjne bazy danych). Za pomocą wbudowanych w system mechanizmów integracji, mamy możliwość elastycznego definiowania danych oraz zachowania systemu w celu importu danych. Dane importowane są do parametrów wybranych zasobów lub bezpośrednio do danych produkcyjnych w przypadku stosowania systemów zarządzania produkcją.
| Również aplikacja AMAGE PVD (Edge Computing) posiada możliwość integracji z zewnętrznymi systemami poprzez tabele wymiany SQL. Należy wybrać odpowiedni model wdrożenia w przypadku, gdy pojawi się takie zapotrzebowanie oraz dostępność kanałów komunikacyjnych. Aplikacja PVD może być uruchomiona na urządzeniach lub serwerach w lokalizacji, gdzie jest bezpośredni dostęp do integrowanych serwerów SQL. |
Zadanie
Chcemy zaimportować z zewnętrznego systemu IT dane. Dane te przekazywane są dla nas przez tabelę wymiany. Dane są okresowo tam wpisywane przez zewnętrzny system IT a naszym zadaniem jest pobranie tych danych, przetworzenie ich w parametry naszych zasobów a następnie usunięcie wykorzystanych już przez nas rekordów z tej tabeli.
Baza danych to test_db. Tabela z danymi to test_table. Kolumnami do importu do jednego parametru to v1 zawierająca dane oraz v2 zawierająca znacznik czasu rejestracji tego parametru. Wszystko to musi trafić do historii parametru ThermalTransmittance dla urządzenia/zasobu SZ2. Po zakończeniu operacji należy odczytane rekordy usunąć.
| Za pomocą definicji tej końcówki mamy możliwość do realizacji kilku różnych scenariuszy. Ten samouczek skupia się tylko na tym zadaniu. |
Definicja końcówki importu
Aby przeprowadzić taki import/eksport danych możemy skorzystać z modułów integracyjnych dostępnych w systemie. Dostęp do nich mamy poprzez sekcję konfiguracyjną oraz menu Wymiana danych.
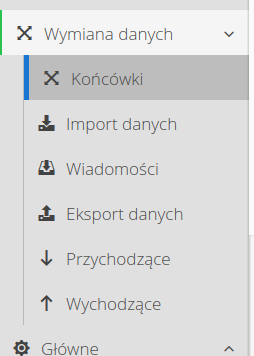
W menu wybieramy akcję Końcówki. Za jej pomocą będziemy mogli zdefiniować nową końcówkę danych, z której będziemy pobierać dane do systemu. Definujemy nową końcówkę. Jest to końcówka z danymi przychodzącymi (będziemy dane pobierać do systemu AMAGE) oraz typ kanału to SQL.
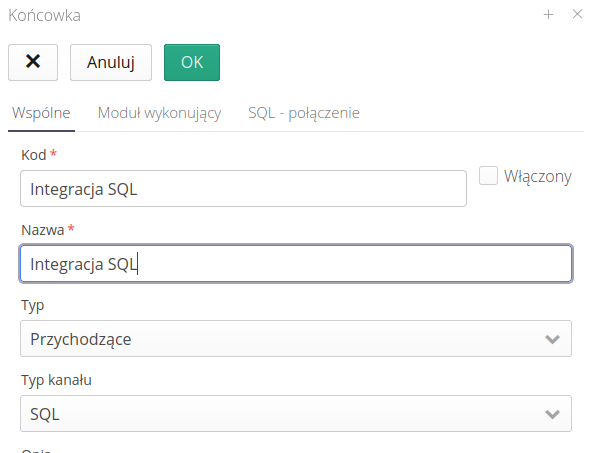
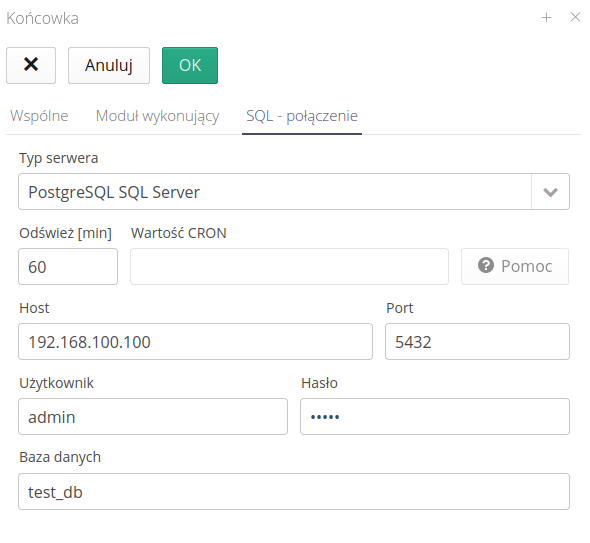
Definiujemy za pomocą kolejnej zakładki podstawowe informacje dotyczące dostępu do danych. Wybieramy serwer, użytkownika, bazę danych oraz okres odświeżania danych/wykonywania operacji.
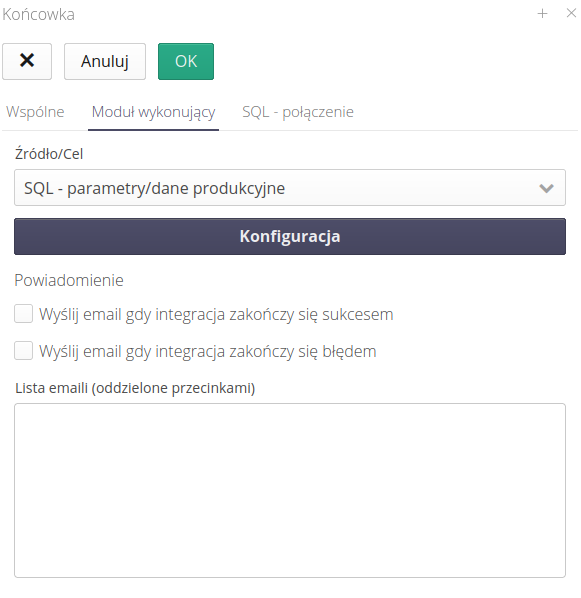
Przechodzimy do zakładki dotyczącej modułu wykonującego operacje. To taki automat, który na podstawie zdefiniowanego źródła danych wykona operacje, które potrzebujemy. Wybieramy akcję SQL - parametry/dane produkcyjne.
Definicja zapytań SQL
Przechodzimy do edycji tego automatu wykonującego operacje. Składa się on z dwóch zakładek z definicją danych. Pierwsza z nich opisuje zapytania SQL niezbędne do wykonania operacji pobrania danych z zewnętrznej tabeli. Tutaj możemy skorzystać z dowolnych zapytań SQL, które zostaną wykonane na docelowej tabeli.
Dodatkowo możemy zdefiniować operację końcową, która zostanie wykonana po zakończeniu operacji pobrania danych.
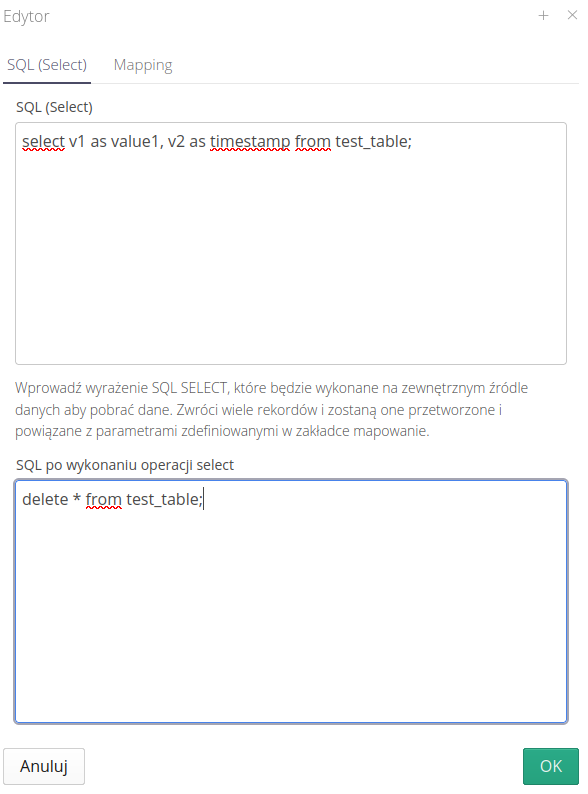
| Zapytania SQL wykonywane są w jednej transakcji, dla której obowiązuje separacja danych. Operacje będą wykonywane tylko na rekordach, które są dostępne w tej transakcji. |
Mapowanie parametrów
Następnie przechodzimy do drugiej zakładki. Tutaj mamy możliwość określenia, gdzie dane, które odczytamy za pomocą zapytań SQL trafią do systemu. Możemy zdefiniować dowolną liczbę takich mapowań. Po utworzeniu nowego mapowania pojawia się okno definicyjne.
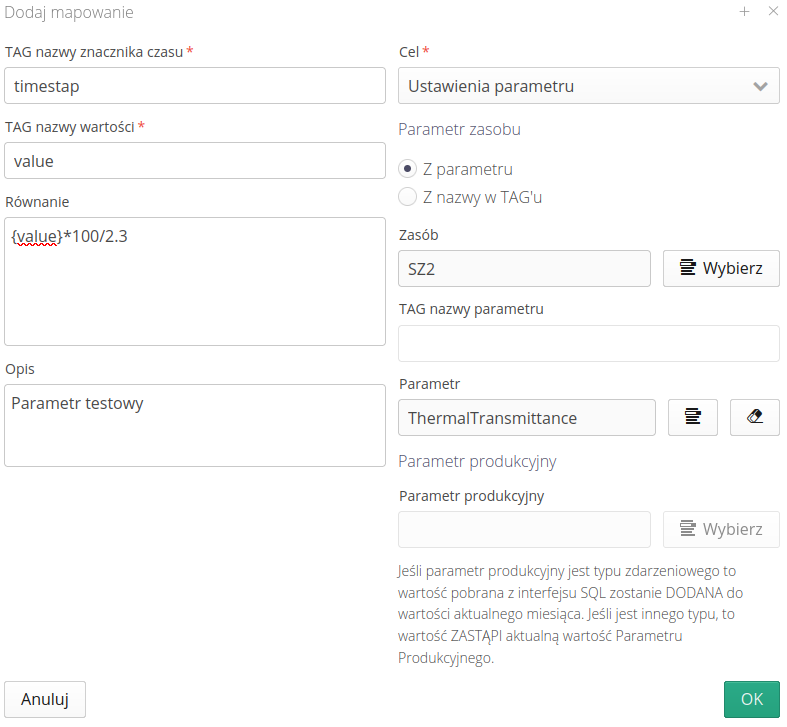
Za pomocą tego okna możemy zdefiniować dane i powiązać je z parametrami w systemie.
-
TAG nazwy znacznika czasu - nazwa kolumny w zapytaniu SQL, która odpowiada znacznikowi czasu (kiedy zostało zarejestrowane dane zdarzenie)
-
TAG nazwy wartości - nazwa kolumny, która zawiera wartość do zapisania (pomiar, tekst itp.)
-
Równanie - za pomocą dodatkowego równania i wykorzystania znacznika
{value}możemy zdefiniować regułę, która przeliczy dany parametr do danych dla nas potrzebnych np. przeliczy wartość z kWh na MWh. -
Opis - dodatkowy opis dla użytkowników edytujących te parametry
-
Cel (ustawienie parametru/dana produkcyjna) - określenie do jakiego elementu ma trafić odczytany rekord. Możemy wybrać albo parametr w zasobie albo daną produkcyjną. W zależności od wybranej opcji, to pozostałe parametry w tej kolumnie są aktywne albo nie.
-
Parametr zasobu - z parametru/z nazwy w TAG’u - możemy określić, czy nazwa parametru jest ustawiona w sposób stały np 'XXX' czy też mamy w kolumnie odczytanych danych określony parametr, który chcemy odczytać.
-
Zasób - zasób, do którego zapiszemy odczytane wartości z tabeli wymiany
-
TAG z nazwy parametru - jeśli włączyliśmy określenie parametru na podstawie danych z zewnętrznego systemu, to tutaj podajemy nazwę kolumny, która określa tą nazwę parametru
-
Parametr - jeśli wybraliśmy jawnie jeden parametr to tutaj go wybieramy z określonego wcześniej zasobu.
-
Parametr produkcyjny - jeśli wybraliśmy zapis do parametru produkcyjnego, to tutaj określamy jego nazwę.
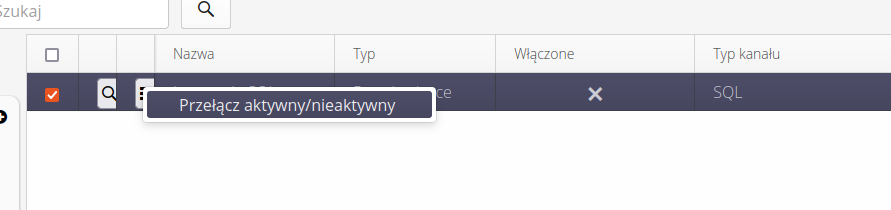
Po zakończeniu edycji możemy też za pomocą menu kontekstowego zmieniać status końcówki z aktywnej/nieaktywnej.
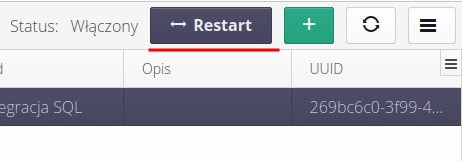
Po zakończeniu edycji końcówki integracji należy pamiętać, aby przekazać systemowi aby przerestartował końcówki i wczytał zapisaną tutaj konfigurację. Wykonujemy to za pomocą przyciski Restart w górnym prawym rogu widoku.
Monitorowanie pracy automatów
Pracę automatów i wszystkie informacje dotyczące wykonywanych zadań możemy podglądać w przeglądarce logów dostępnej również w sekcji konfiguracyjnej.
Gotowe ! Dane skonfigurowane i zostają przesyłane pomiędzy systemami.
| Howto powstało na bazie wersji systemu 1.21.0.0 (03.2023) oraz przedstawia funkcje, które mogą nie być dostępne w Twoim systemie. Zapytaj AMAGE o udostępnienie tej funkcjonalności. |
| Ze względu na ciągły rozwój systemu niektóre ekrany lub pliki konfiguracji mogą wyglądać nieznacznie inaczej, ale zachowają nadal pełną funkcjonalność tutaj opisaną. Nie wpływa to na zasadnicze funkcje opisywane w tym dokumencie. |