Integracje danych
Zestaw funkcji i modułów odpowiedzialnych za wymianę informacji pomiędzy systemem AMAGE z systemami zewnętrznymi lub innymi źródłami danych.
Importer
Wymiana danych umożliwia dostęp do mechanizmów, które pozwalają na transfer danych do systemu AMAGE lub przenosić dane z systemu AMAGE do innych źródeł.
Importery danych dostępne dla szeregu obszarów pozwalają na import danych ze źródeł typu arkusz Excel™ wraz z możliwością definicji przez użytkownika wszystkich niezbędnych danych konfiguracyjnych. Pozwala to na elastyczną konfigurację parametrów samodzielnie przez wszystkich użytkowników.
Po wejściu do opcji przez główne menu użytkownikowi przedstawiana jest lista dostępnych importerów.
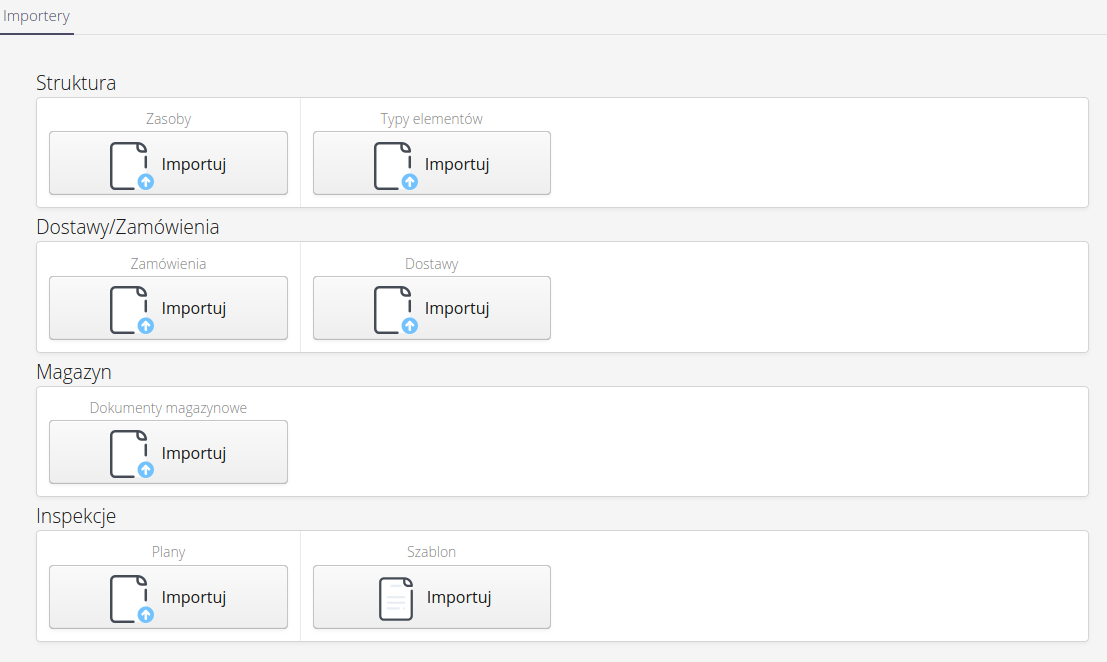
| Lista importerów zależy od aktywnych dla danej instancji modułów i jest zmienna dla każdego typu instancji. |
Importery dzielą się na masowe - tj. umożliwiają import wielu rekordów ze źródeł typu arkusz XLS lub pojedyncze tj. takie, które umożliwiają import jednego elementu w dedykowanych formatach (XML, JSON itp.). Wykorzystywane głównie do przenoszenia danych konfiguracyjnych pomiędzy instancjami (np. profile dostępu.)
Importy masowe dostępne w systemie to m.in.:
-
Struktura - zasoby - możliwość importu zasobów do struktury systemu wraz z utworzeniem wszystkich niezbędnych dodatkowych danych (typy, grupy produktów, lokalizacje itp.)
-
Struktura - typy elementów - import typów asortymentu do systemu
-
Dostawy/Zamówienia - zamówienia - import listy zamówień
-
Dostawy/Zamówienia - dostawy - import listy dostaw
-
Magazyn - dokumenty magazynowe - import dokumentów magazynowych
-
Inspekcje - plany - import planów inspekcji
Pojedyncze importy
-
Inspekcje - szablon inspekcji - import szablonu inspekcji
Importy definicyjne
Importy masowe posiadają interfejs ujednolicony z dodatkową możliwością konfiguracji specyficznych opcji dla każdego z importera z osobna.
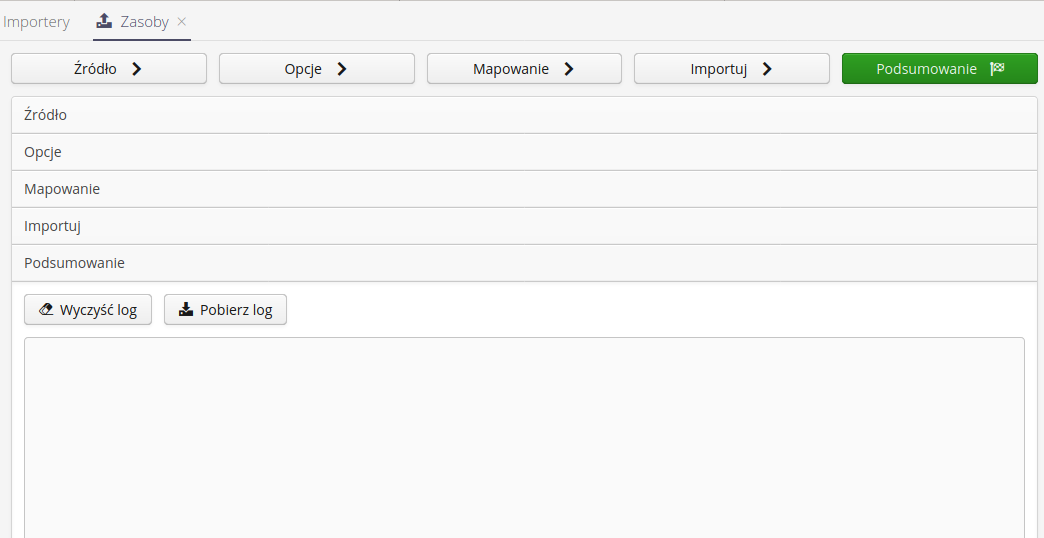
Importy dzielą się na kilka etapów:
-
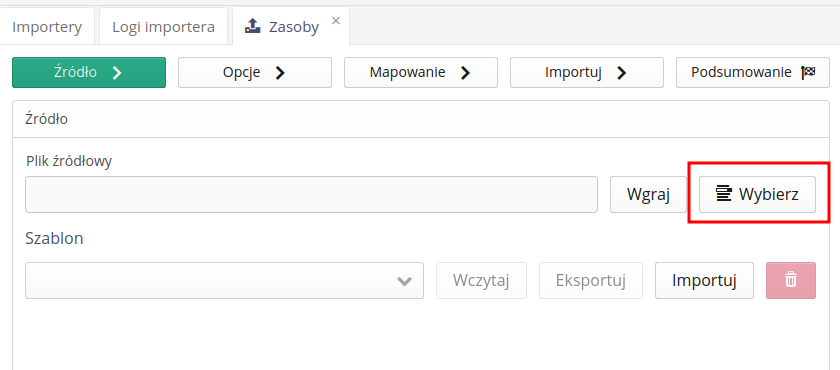
Wybór źródła danych - wybór pliku źródłowego do importu. System wczytuje ten plik i umożliwia dalsze operacje na nim. Plik możemy wybrać z lokalnego dysku użytkownika lub wybrać pliki z archiwum plików w systemie.
-
Wybór zapisanego mapowania - mapowanie kolumn w źródłowym pliku oraz opcje specyficzne dla wybranego importera mogą być zapisane do późniejszego wykorzystania. Pozwala to na powtórzenie importu wielokrotnie z wykorzystaniem zapisanych danych w systemie.
-
Opcje - opcje specyficzne dla wybranych importerów. Jeśli importer nie posiada specyficznych opcji, to ten krok jest pomijany. Opcje opisane są poniżej z podziałem na wybrane importery.
-
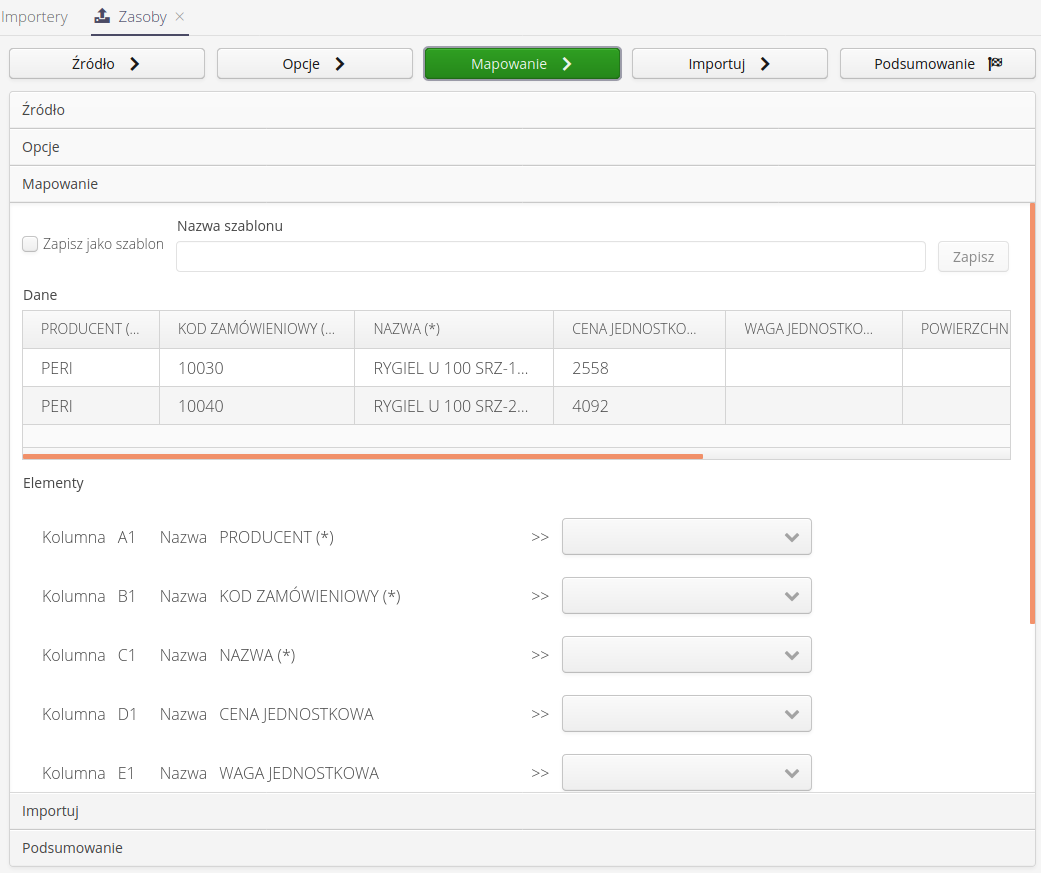
Mapowanie danych - mapowanie danych to kluczowy element importera. W górnej części okna wyświetlane są dwa pierwsze rekordy oraz opisy kolumn (z pierwszego rzędu pliku źródłowego), które pozwalają w łatwiejszy sposób zwizualizowanie co system widzi w poszczególnych kolumnach. Dolna część to lista wszystkich kolumn występujących w danym pliku źródłowym z możliwością wskazania co dla importera znaczy każda kolumna. Jeśli jakieś kluczowe dane w mapowaniu nie są określone, to podczas próby przejścia dalej system wyświetli odpowiedni komunikat. W tym miejscu użytkownik ma możliwość zapisania mapowania do wykorzystania w późniejszych wykonaniach importu.
-
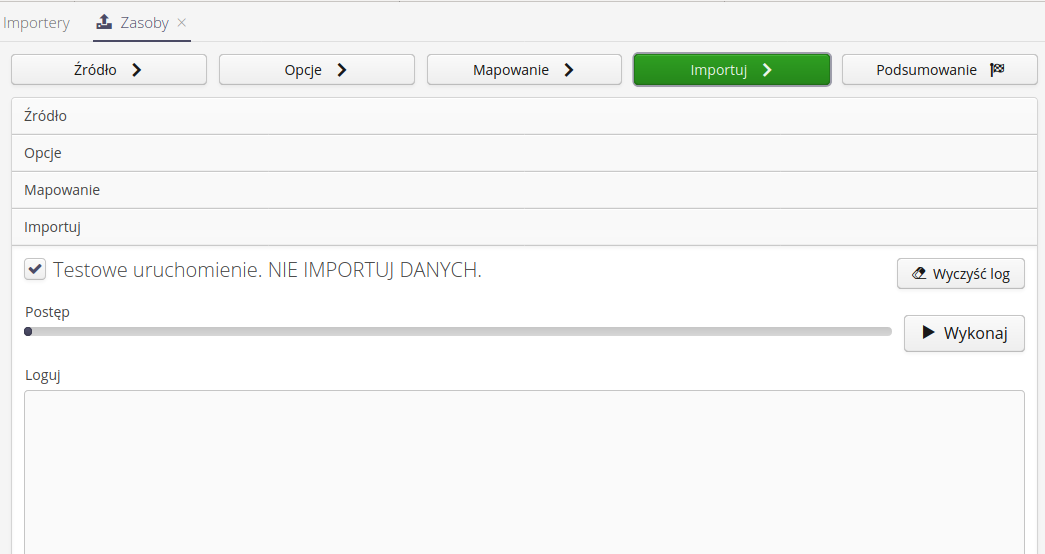
Import - po przejściu do tego kroku wszystkie dane są dostępne i system umożliwia wykonanie importu danych. Dane te uruchamiamy przez wybranie przycisku Wykonaj. Operacja wykonywana jest na serwerze i wynik przedstawiany jest w oknie logów. Wyczyścić okno logów można poprzez wybranie przycisku Wyczyść log.
-
Podsumowanie umożliwia przegląd danych logowania w całym procesie, przeglądnięcie podsumowania dotyczącego ilości rekordów obsłużonych w całym procesie. Użytkownik ma możliwość wyczyszczenia logu przez akcję Wyczyść log lub pobrania i zapisania lokalnie tekstu logów przez wybranie akcji Pobierz log.
| Każdy import dodatkowo jest zapisywany w systemie w dedykowanej tabeli w bazie danych, co umożliwia późniejszy dostęp i analizę wykonywanych importów przez wszystkich użytkowników systemu. |
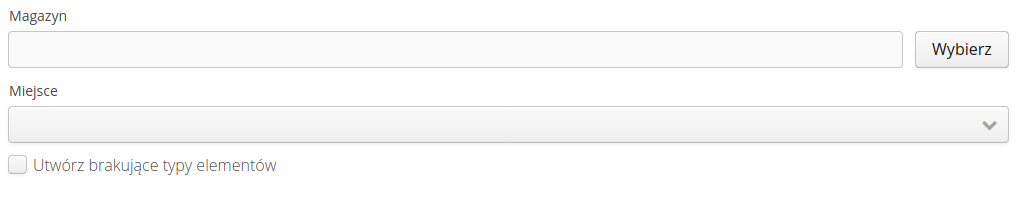
Magazyn - opcje
Opcje podczas importu dokumentów magazynowych pozwalają wybrać docelowy magazyn i miejsce składowania dla importowanych dokumentów oraz umożliwia utworzenie brakujących typów elementów w asortymencie podczas realizacji procedury importu.
Funkcja - import dokumentów z parametrami
| Funkcjonalność dostępna w momencie włączenia śledzenia materiałów w magazynie/dostawach z wykorzystaniem dodatkowych parametrów. |
Importer dokumentów magazynowych został rozbudowany o możliwość importu elementów magazynowych do określonych materiałów specyfikowanych za pomocą dodatkowych parametrów. Pozwala to na wprowadzenie/wydanie materiału dokładnie z określonego typu elementów wraz z jego parametrami np. certyfikat, wytop

Plany inspekcji - opcje
Opcje podczas importu planów inspekcji pozwalają na utworzenie typów asortymentu oraz dedykowanych parametrów nadzorowanych przez plany inspekcji.

Zasoby - opcje
Opcje importu zasobów są najbardziej rozbudowane i umożliwiają konfigurację wielu dodatkowych funkcji podczas importu dostosowując się do źródłowego pliku importu.
-
Opcje ogólne pozwalają na definicję podstawowych opcji importu oraz wskazaniu miejsc importu i parametrów, które służą do wyszukania w systemie czy dany zasób już w nim istnieje (wtedy aktualizowane są tylko parametry zasobu zamiast tworzyć go na nowo)
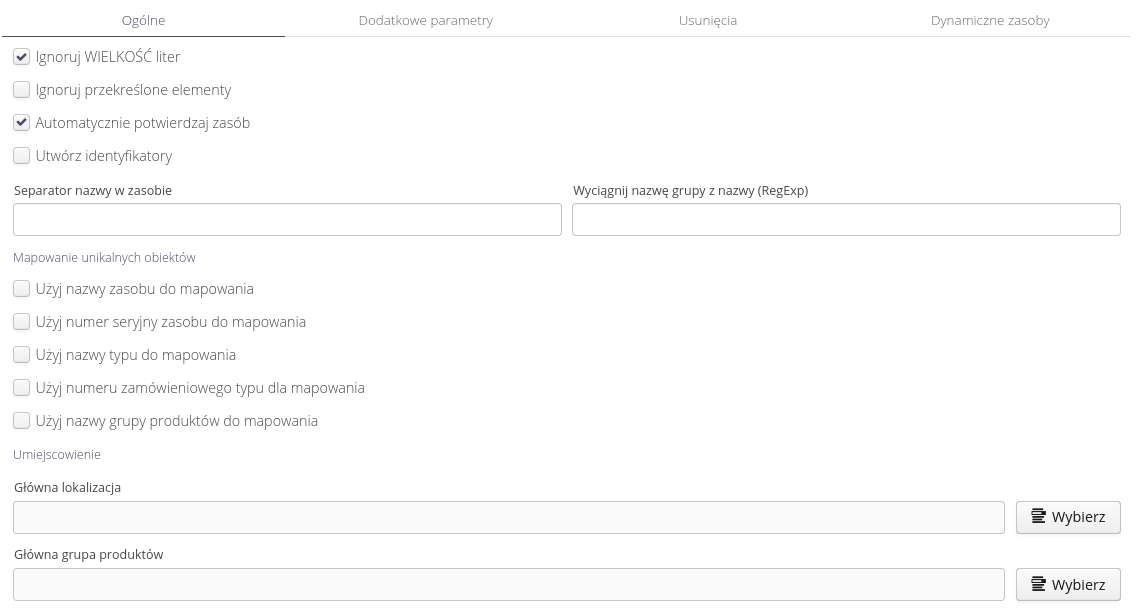
| W przypadku, gdy w danych wejściowych zostanie określony numer seryjny urządzenia, to AUTOMATYCZNIE zostanie włączone wyszukiwanie istniejącego zasobu względem numeru seryjnego i istniejący zasób zostanie zaktualizowany zamiast tworzyć nowy zasób. Należy to uwzględnić w procedurze importu i definicji danych ! |
-
Dodatkowe parametry pozwalają na definicję dodatkowych parametrów w typie elementów oraz wartości w zasobie. Pozwala to na import dowolnych danych do zasobów, które nie są domyślnie predefiniowane w systemie.
-
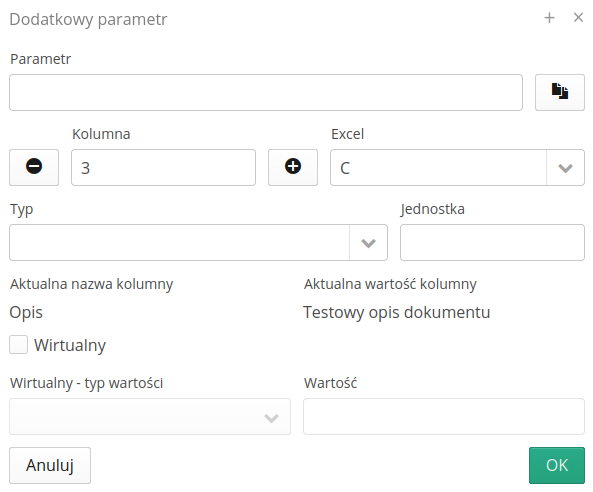
Definicja dodatkowego parametru pozwala na określenie kolumny, w której ten parametr się znajduje lub określenie parametru jako wirtualny tj. taki, który nie istnieje domyślnie w źródłowym pliku, ale chcemy, aby taki parametr się pojawił w importowanych danych. Typ wartości parametru wirtualnego może być określony jako bezpośrednia wartość tekstowa albo aktualna data & czas lub sama data/czas. Pozwala to na wprowadzenie do dowolnego wirtualnego parametru daty i czasu wykonania importu danych.
Pole Aktualna wartość kolumny pokazuje wartość wybranej komórki w pierwszym rzędzie danych. Aktualna nazwa kolumny to nazwa kolumny w pierwszym rzędzie danych.
-
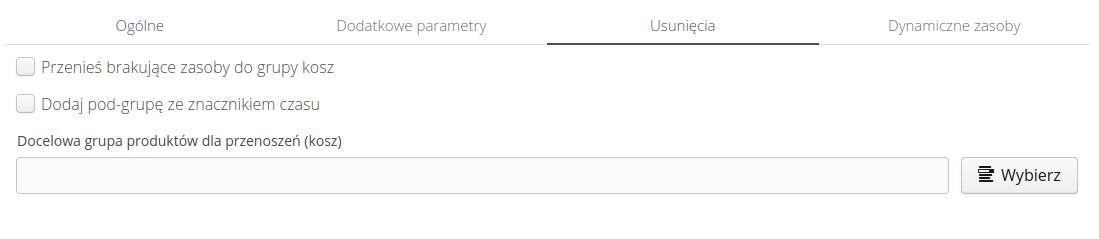
Usunięcia zasobów pozwalają na definicję zachowania systemu w przypadku, gdy w systemie znajduje się zasób, który nie istnieje w źródłowych danych. Pozwala to na korektę listy zasobów w systemie na podstawie dostarczonego źródła danych. Ze względów bezpieczeństwa importer nigdy nie kasuje zasobów, jedynie przenosi je do wybranej grupy produktów. Umożliwiamy również utworzenie w wybranej grupie - podgrupy z nazwą będącą aktualną datą wykonania procedury.
-
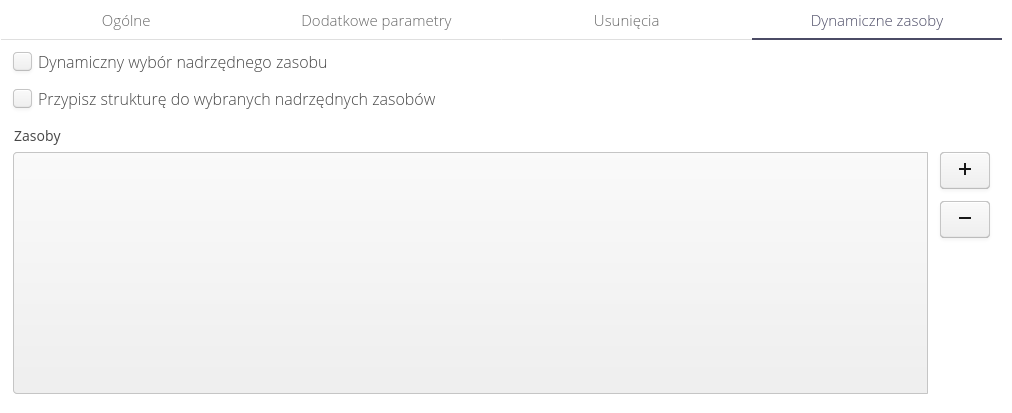
Importer umożliwia import danych jako zasoby podrzędne w stosunku do zasobów istniejących w systemie. Opcje te umożliwiają określenie do jakich istniejących zasobów zaimportować dane jako zasoby podrzędne.
W importerze zasobów dodano możliwość zdefiniowania dodatkowych parametrów bezpośrednio z zakładki (etapu) mapowania pól importowanych.
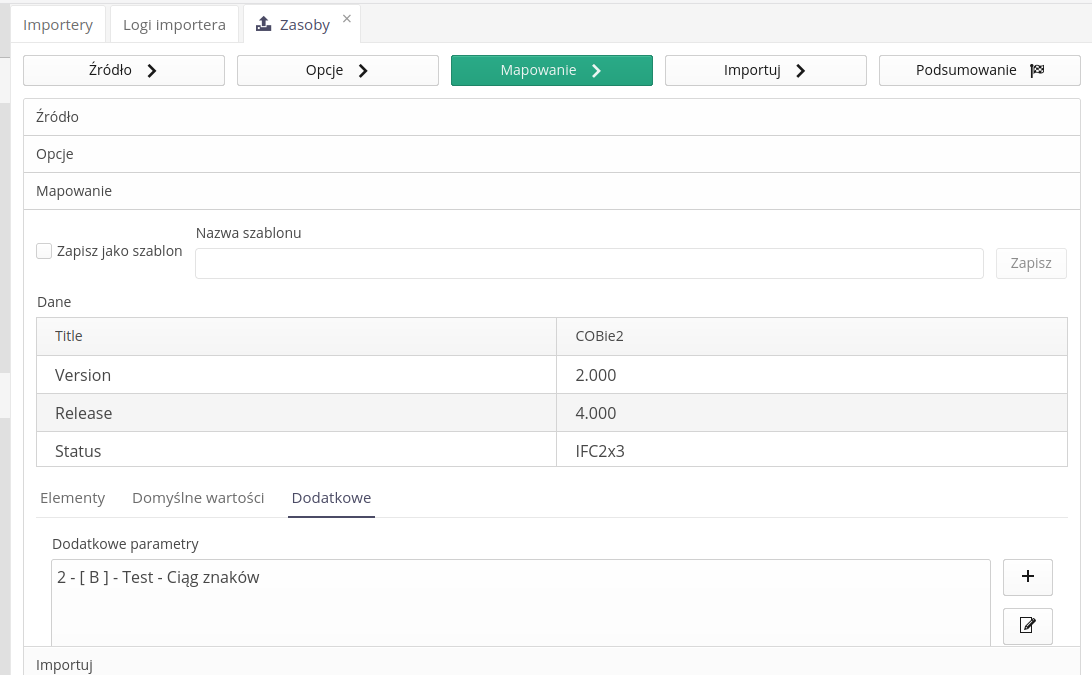
W parametrach istnieje możliwość podania kodu parametru zgodnie z nomenklaturą Excel i jednostkę parametru
W importerze zasobów dodano możliwość wprowadzenia parametrów dodatkowych poprzez podanie kodu zgodnego z nomenklaturą Microsoft Excel tj. kolumny A-ZZZ. Za pomocą tej formy określenia kolumny systemu automatyczne ją przelicza na indeks kolumny.
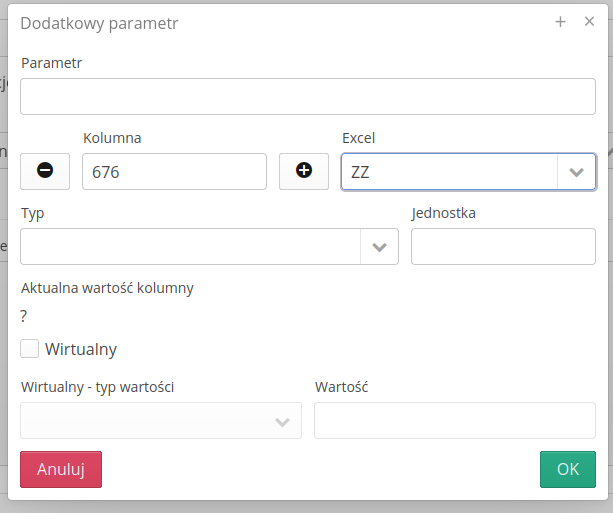
Do importera zasobów dodano możliwość importu identyfikatorów oraz określenia typu importowanego identyfikatora.
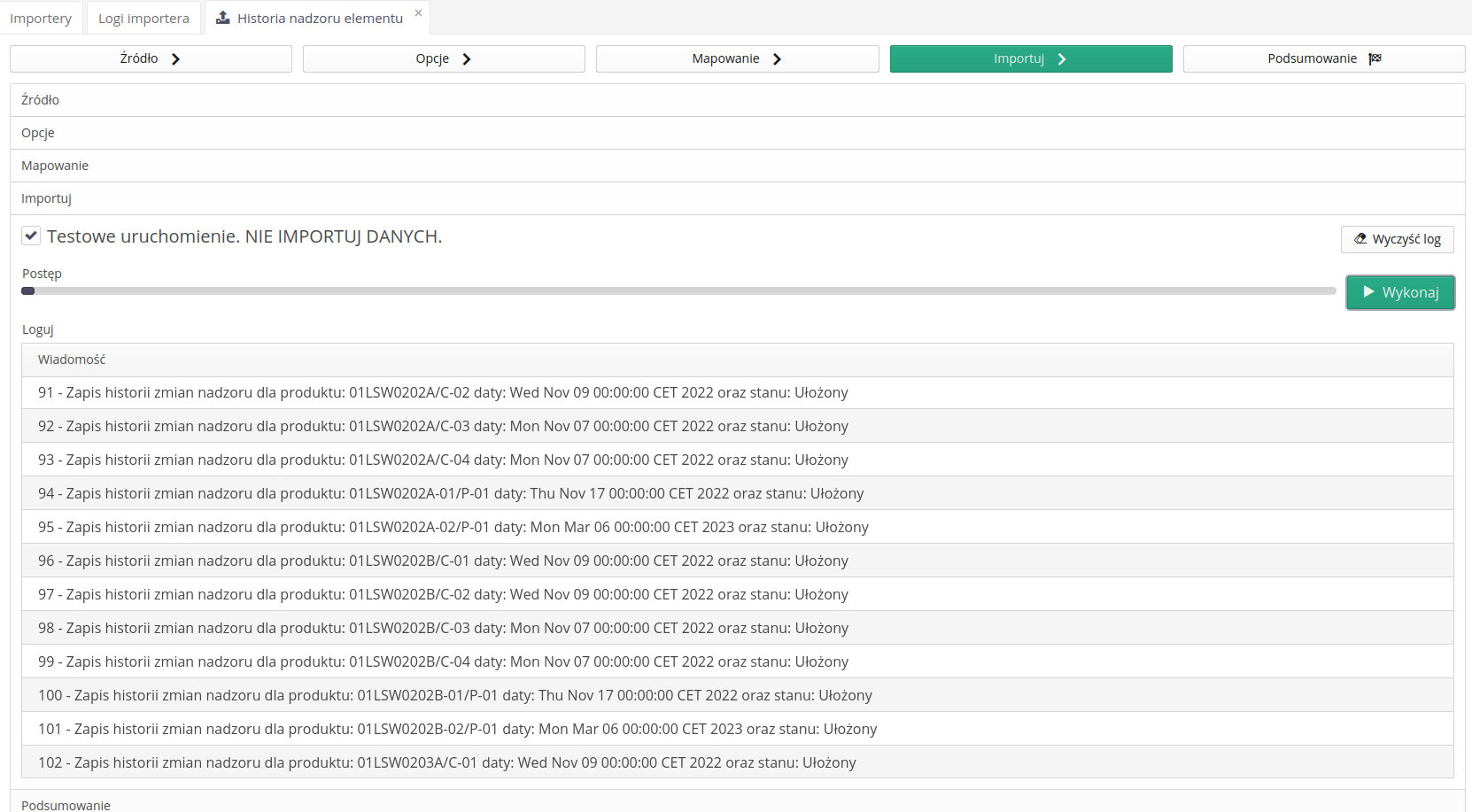
Historia nadzoru
Importer historii nadzoru pozwala zaimportować zapisy zmiany stanów z pliku XLSX. Za pomocą importera definiujemy:
-
parametry, które pozwalają na wybór zasobu - nazwa, nr seryjny, nr inwentarzowy
-
dodatkowe parametry, które będą importowane razem ze zmianą stanu (nadzorowane parametry)
-
mapowanie kolumn - definicja zmiany stanu, nazwy stany, daty, osoby
Po zdefiniowaniu tych danych importujemy wszystko przy pomocy jednego importu danych.
Importer - typy elementów
Dla importera typów elementów dodano możliwość importu wszystkich danych finansowych i magazynowych znajdujących się w rozszerzeniu informacji pochodzących z modułów magazynowych, dostaw i dzierżawy.
Importery - importer parametrów do typów (osobny)
Dodano osobny typ importera. Importer parametrów dla typów elementów. Dodano go oprócz już istniejącej możliwości definicji parametrów w ogólnym importerze typów elementów. Za jego pomocą można zaimportować parametry do typów w uproszczony sposób za pomocą osobnego, dedykowanego importera.
Parametry typów
Importery - importer mapowania dokumentacji
Dodano importer mapowania dokumentacji. Za jego pomocą mamy możliwość zaimportowania dodatkowego mapowania dokumentacji tj. wskazania dla określonego zasobu, w którym miejscu załączników znajduje się określona część dokumentacji np. schematy jednokreskowe elektrycznego urządzenia na stronach 11-23 w dokumentacji liczącej 1000 stron. Ułatwia to nawigację i szybki dostęp do danych.

Importer - importer wykonań inspekcji
Dodano do systemu importer wykonań inspekcji. Za jego pomocą mamy możliwość zaimportowania historii wykonań inspekcji lub inspekcji wykonanych przez zewnętrzne osoby/firmy.


Importer - zdarzenia serwisowe
Importer zdarzeń serwisowych pozwala na zaimportowanie zdarzeń serwisowych z zewnętrznych źródeł. Ułatwia to import danych z zewnętrznych systemów do systemu AMAGE np. podczas przenoszenia danych z innych systemów CMMS.
W przypadku importera mamy możliwość zdefiniowania:
-
Mapowanie istniejących obiektów - określenia, w jaki sposób znajdujemy zasoby w systemie, do których zostanie dołączone dane zdarzenie serwisowe.
-
Importer mapowania pól pozwala na określenie kolumn zawierających m.in. stan zdarzenia, opis, typ zdarzenia, osoba, termin,
Po zaimportowaniu zdarzenia są powiązane z zasobem w systemie AMAGE i zawierają wszystkie niezbędne informacje do zachowania historii zdarzeń serwisowych.
Importy pojedyncze
Importy pojedyncze pozwalają na import pojedynczych rekordów z zewnętrznych systemów. Najczęściej wykorzystywane to jest do importu danych konfiguracyjnych z innych instancji np. ustawień profili dostępu, szablonów i definicji danych.
Import podzielony jest na cztery etapy.
-
Wybór źródła danych - wybór pliku źródłowego do importu. System wczytuje ten plik i umożliwia dalsze operacje na nim
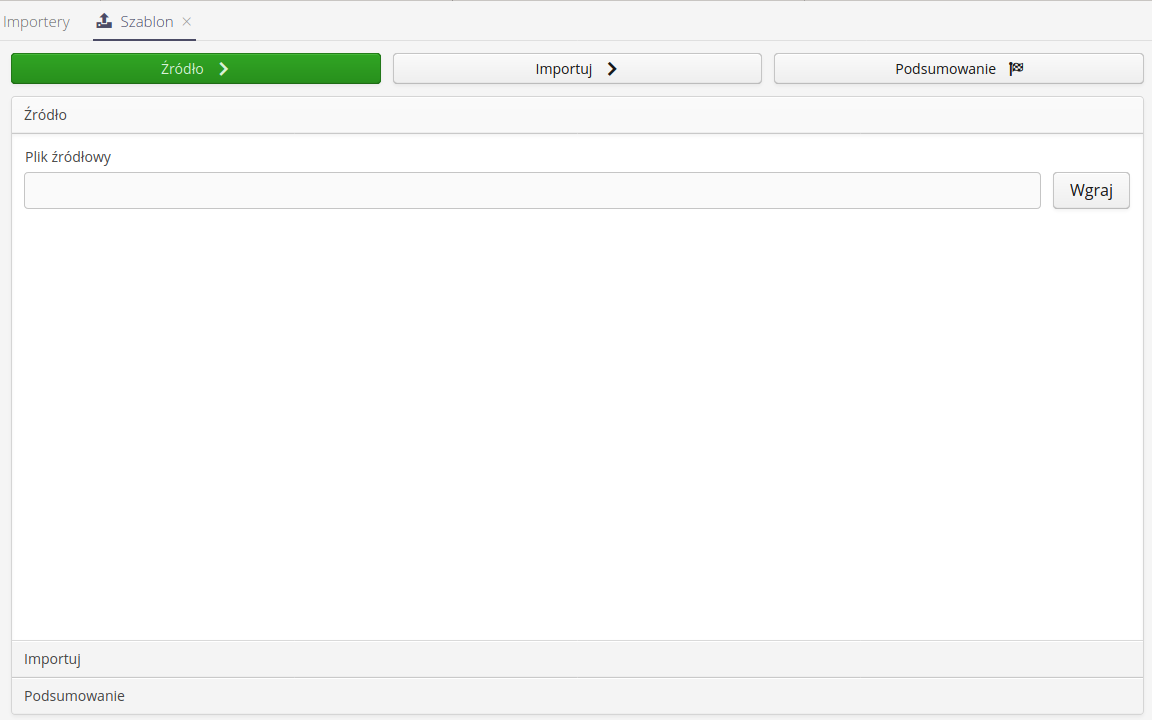
Dla importerów pojedynczych istnieje możliwość określenia dodatkowych parametrów takiego importu.
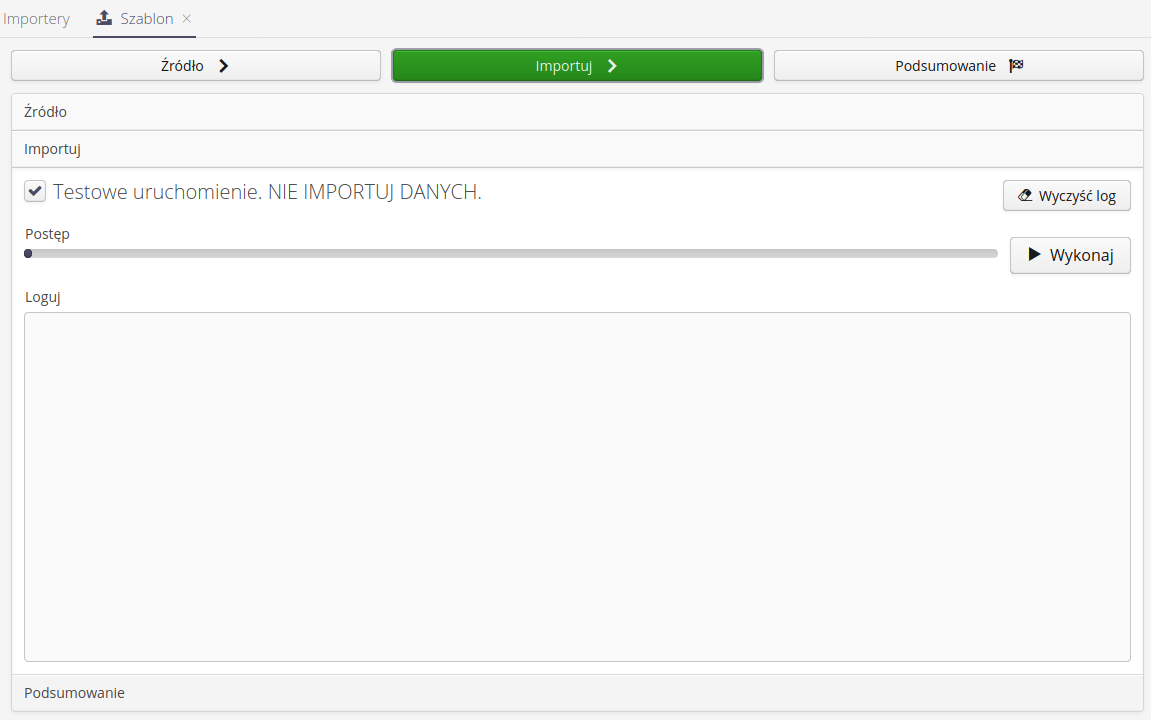
Pojawił się dodatkowy krok Opcje w kreatorze importu.

-
Import - po przejściu do tego kroku wszystkie dane są dostępne i system umożliwia wykonanie importu danych. Dane te uruchamiamy przez wybranie przycisku Wykonaj. Operacja wykonywana jest na serwerze i wynik przedstawiany jest w oknie logów. Wyczyścić okno logów można poprzez wybranie przycisku Wyczyść log.
-
Podsumowanie umożliwia przegląd danych logowania w całym procesie, przeglądnięcie podsumowania dotyczącego ilości rekordów obsłużonych w całym procesie. Użytkownik ma możliwość wyczyszczenia logu przez akcję Wyczyść log lub pobrania i zapisania lokalnie tekstu logów przez wybranie akcji Pobierz log.
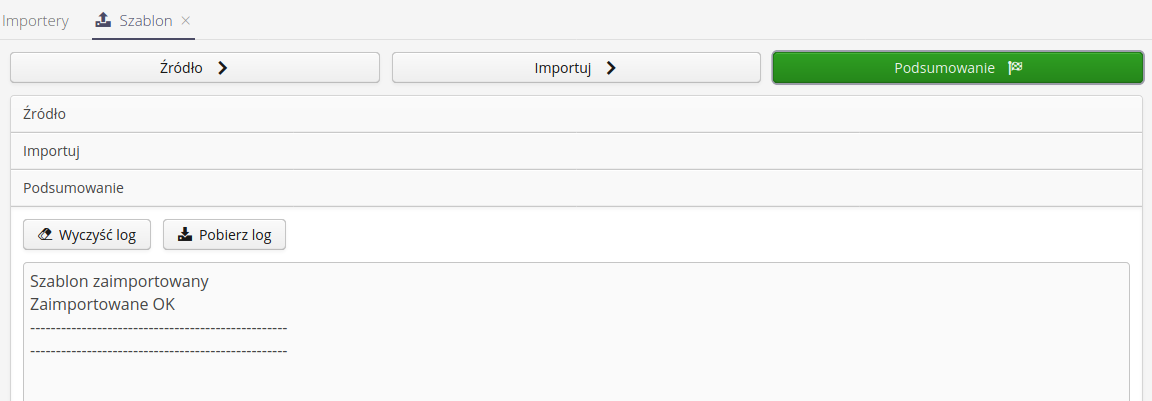
| Wszystkie logi z procesu importu pojedynczych elementów również są zapisywane do późniejszego przeglądania. Dane te dostępne są w przeglądarce logów z informacjami o czasie/osobie wykonującej ten import. |
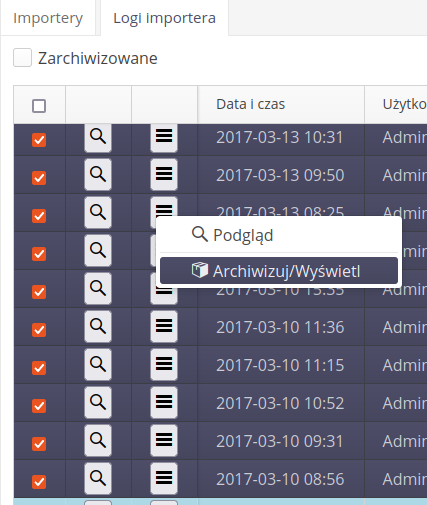
Lista logów importu pozwala na przeglądanie wszystkich operacji oraz dostęp do logów.

W przypadku gdy import był testowy lub zakończył się błędem, to te dane zostają odpowiednio wyświetlone w oknie.
W liście importerów/eksporterów pojawiają się szczegółowe logi wynikające z wykonanych czynności importu/eksportu. Dodano możliwość archiwizacji wybranych logów. Logi w tym przypadku znikają z listy, ale są dostępne w archiwum.
Importer - IFC
Importer IFC pozwala na import danych do systemu tj. struktura zasobów bezpośrednio z plików IFC. System stara się automatycznie wykryć strukturę danych w pliku IFC i na tej podstawie tworzy zasoby w systemie AMAGE wraz z lokalizacjami, grupami elementów, systemami i typami elementów. Nie wszystkie pliki IFC posiadają bezpośrednią i pełną informację. Często w dodatkowych parametrach projektanci przechowują informacje dotyczące głównych pól w systemie AMAGE tj. nazwie zasobu, typie elementów, producencie itp. Wynika to z tego, że pliki IFC są zwykle tworzone w programach CAD i nie zawierają pełnej informacji o zasobach lub zawierają informacje ogólne dotyczące standardowych struktur np. okno, a dopiero w parametrach znajduje się szczegółowa informacja o typie, producencie oraz dodatkowych parametrach określonego egzemplarza okna. W przypadku importu z plików IFC w importerze mamy możliwość zdefiniowania dodatkowych opcji takich jak:
-
Aktualizuj zasób - po Global ID - pozwala na wyszukanie zasobu w systemie na podstawie jego identyfikatora GlobalId, a nie jego nazwy. Ma to znaczenie w przypadku aktualizacji nazw elementów jednocześnie zachowując w systemie projektowym ten sam GlobalId.
Dodatkowe parametry i mapowanie
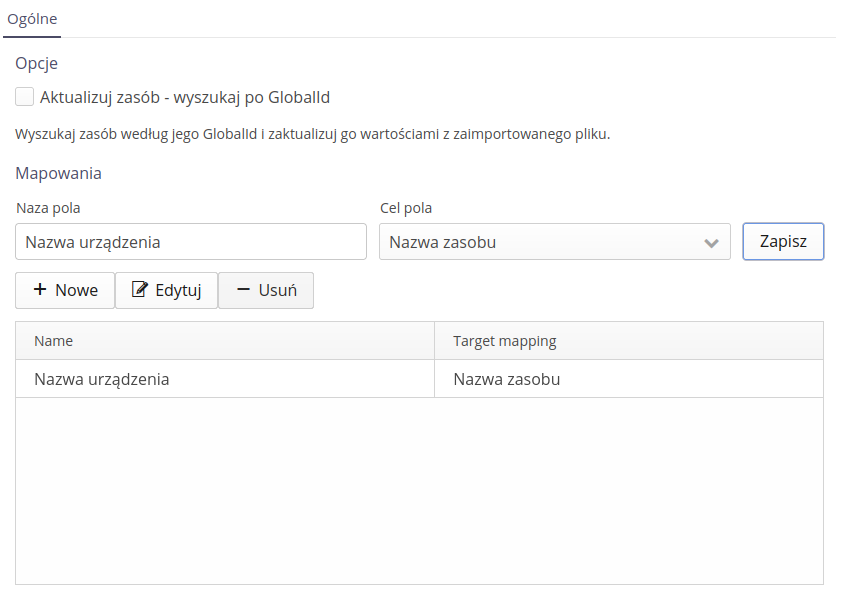
Importer importuje wszystkie parametry do zasobów. Natomiast za pomocą tego mapowania mamy możliwość określenia dodatkowego znaczenia danego parametru np. nazwa producenta, typ elementu lub inne kluczowe informacje, które chcemy wykorzystać w systemie AMAGE.
Definiujemy mapowanie za pomocą wskazania nazwy pola oraz docelowego elementu w zasobie.
Importer - COBie
Importer formatu COBie został wyposażony w dodatkowe opcje, z których jedna z nich pozwala na zdefiniowanie dynamicznego wykrywania położenia danych w poszczególnych arkuszach danych. Domyślnie system wykrywa położenie danych na podstawie ich rozmieszczenia we wzorcowych szablonach. Dla importera danych COBie zdefiniowano możliwość określenia zakresu importowanych danych. Można wybrać jakie elementy (arkusze) zostaną zaimportowane do systemu AMAGE na podstawie tych
W przypadku zmiany formatu i włączeniu tej opcji, system dynamicznie wykrywa dane w kolumnach na podstawie tekstu z nagłówka.
| Tekst w nagłówku musi odpowiadać tekstowi z wzorcowych danych importu formatu COBie. |
Dla importera formatu COBie dodano możliwość importu arkusza atrybutów i ich wartości. Wszystkie dane tam zawarte zostają zaimportowane do powiązanych zasobów (komponentów).
| Atrybuty importowane są tylko dla zasobów (komponentów) z arkusza COBie. |
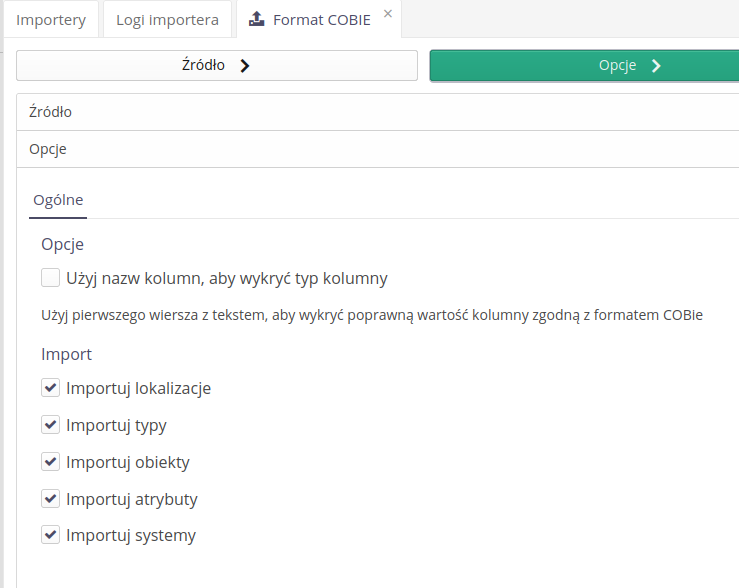
Importer - COBie - importer arkusza Documents
Dla formatu COBie zaimplementowano dodatkowy mechanizm importu pozwalający na zaimportowane plików z arkusza Document standardu COBie.
Pliki wraz z arkuszem COBie przesyłane są na serwer AMAGE, który automatycznie importuje je do określonych zasobów/komponentów.


Eksporter
Eksportery stanowią mechanizm odwrotny do importu, czy pozwalają na wyeksportowanie wybranych danych z systemu AMAGE do zewnętrznego pliku danych.
Dostęp do eksporterów jest możliwy z widoku konfiguracyjnego z sekcji Wymiana danych.
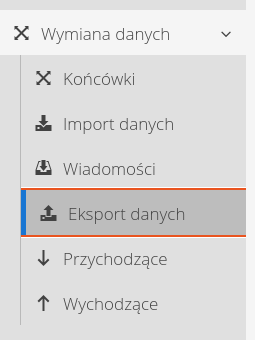
Po wybraniu eksporterów, ładuje się widok z listą wszystkich możliwych eksportów w danej instancji systemu. Dostępne formaty i zakresy danych zależą od konfiguracji systemu i dostępnych/wdrożonych modułów funkcjonalnych.
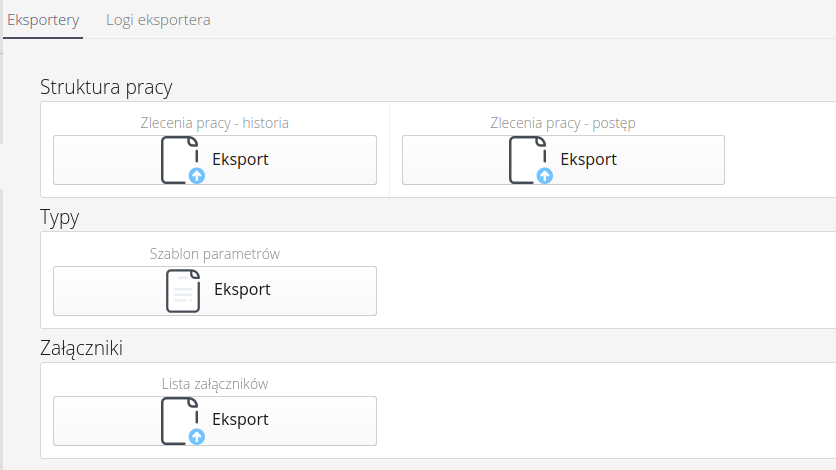
Eksportery w AMAGE dzielą się na dwa typy:
-
masowe - tj eksportują wszystkie/wybrane rekordy z danego zakresu np. rejestracje obecności
-
pojedyncze - w przypadku, gdy udostępniamy możliwość eksportu wybranego rekordu w specyficznym dla niego formacie (np. XML). Wykorzystywane jest to zwykle w migracjach określonych konfiguracji systemu do innej instancji (np. innej budowy) wykorzystując już utworzone dane w poprzedniej instancji.
Po wybraniu dowolnego eksportera masowego przechodzimy do standardowego - ujednoliconego - widoku eksporterów. Proces dzieli się na cztery etapy - wskazanie źródła danych, mapowanie dostępnych w obiekcie pól na pola eksportowane w arkuszu wynikowym, rzeczywisty proces eksportu z monitorowaniem postępu oraz podsumowanie całego procesu.
Przechodząc do pierwszego kroku Źródło mamy możliwość wyboru docelowego formatu eksportowanych plików.
Obecnie dostępne formaty to:
-
CSV - wg. RFC4180 - format CSV zgodny z normą RFC opisującą separator danych oraz inne specyficzne dane dotyczące formatu.
-
XLSX - format XML zgodny z formatem Microsoft® Excel XLSX
| Kodowanie znaków zawsze w danych eksportowanych z systemu AMAGE jest w stronie kodowej UTF-8. |
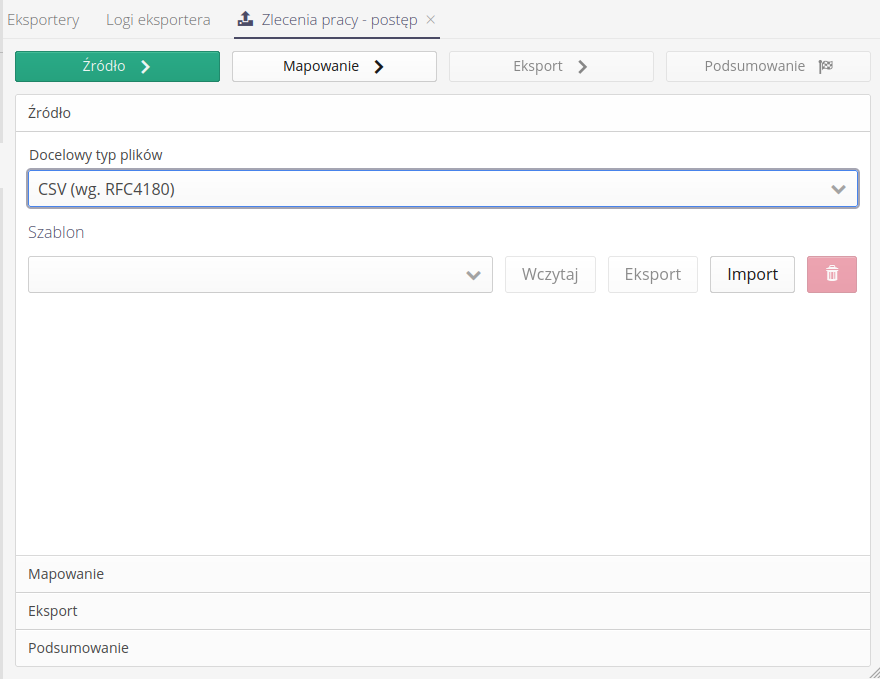
W tej sekcji możemy również wczytać zapisany szablon eksportu. Mechanizm tożsamy z danymi w module importu danych. Możemy wczytać szablon z wewnętrznej bazy danych, wyeksportować do formatu JSON i przenieść do innej lub zaimportować z innej instancji.
Kolejnym krokiem jest mapowanie pól eksportu. Za jego pomocą możemy określić jakie pola zostaną wyeksportowane oraz w jakiej kolejności. Dostępne są w widoku możliwości:
-
Dodaj wszystkie - dodaje wszystkie dostępne elementy do pól eksportowych
-
Dodaj element - dodaje jeden pusty element eksportu, który określimy w dalszym etapie.
-
Góra/Dół/Usuń - przesunięcie kolejności eksportu lub usunięcie pola z eksportowanych danych.
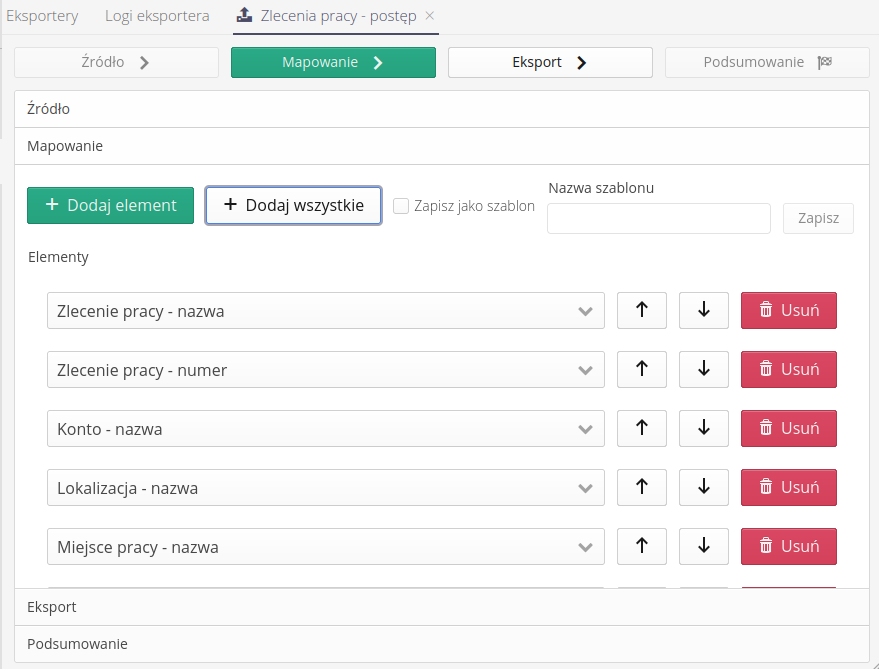
W tym interfejsie możemy zdefiniować co i w jakiej kolejności znajdzie się w poszczególnych kolumnach danych. Utworzone mapowanie możemy zapisać jako szablon gotowy do wykorzystania w późniejszym czasie.
| Istniejące mapowanie eksportu możemy wykorzystać również w automatyzacji eksportu. Poprzez definicję końcówki eksportu np. na adres email możemy automatycznie eksportować wybrany zakres danych i przesyłać je automatycznie do zewnętrznego odbiorcy. |
Przechodząc do kolejnego kroku wykonujemy eksport danych.
W logu pojawiają się informacje szczegółowe dotyczące wykonywanych czynności.
Jeśli proces zakończy się sukcesem, to zostanie włączony przycisk Pobierz wynik.
Za jego pomocą możemy pobrać plik będący wynikiem eksportu.
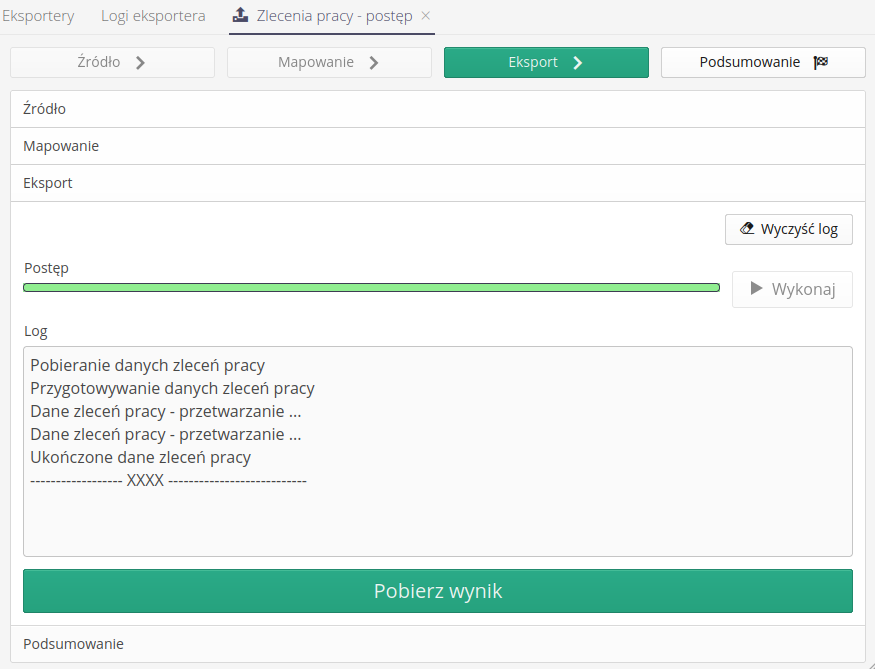
Dostępne w tym widoku akcje:
-
Wykonaj - wykonaj eksport, zbierz dane i sformatuj je zgodnie z mapowaniem
-
Wyczyść log - wyczyść log postępu prac
-
Pobierz wynik - pobierz wynik eksportu (plik)
Po zakończeniu operacji możemy przejść do podsumowania, przeglądnąć szczegółowy log eksportu, zapisać go lokalnie.
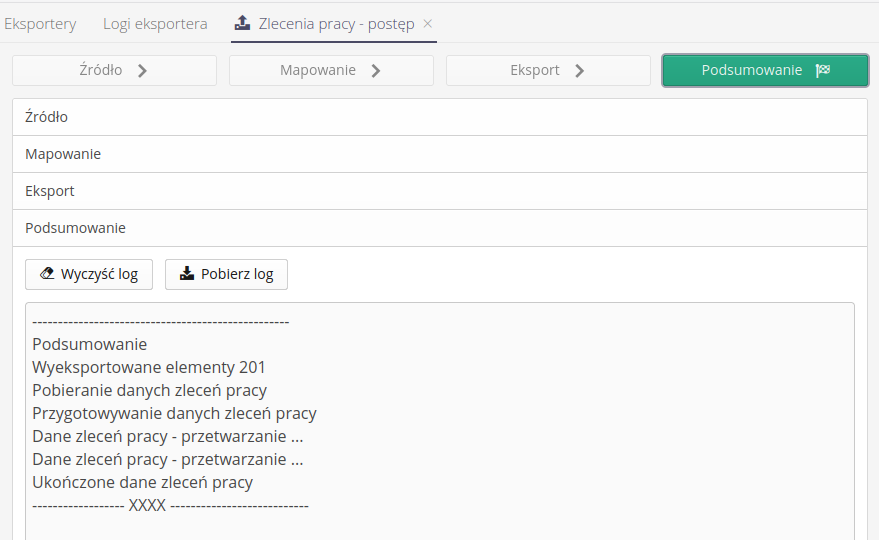
Wszystkie procedury eksportu/importu dostępne są w postaci zapisanych w bazie danych logów. Możemy je przeglądać i sprawdzić mechanizm i funkcje wywoływane przez użytkowników.
W przypadku gdy eksport był testowy lub zakończył się błędem, to te dane zostają odpowiednio wyświetlone w oknie.
Eksport pojedynczy
Niektóre elementy w liście możliwych obiektów do eksportu posiadają inną ikonę. To są eksporty tzw. pojedyncze. W tym przypadku eksportujemy nie wszystkie dostępne rekordy danego typu w systemie, tylko pojedynczy rekord/obiekt.
| Eksporty pojedyncze powstały ze względu na konieczność eksportu danych z systemu AMAGE w określonym formacie typu XML, JSON. Dane przenoszone powinny mieć jednostkowy charakter tj. przenosimy tylko jeden z elementów zamiast wszystkie rekordy. Dodatkowo taki format eksportu może być dużo bardziej zaawansowany i łączący wiele tabel w jednym pliku np. szablony inspekcji. |
Po wybraniu dowolnego obiektu z formatem pojedynczego eksportu pojawia się okno procesu eksportowania.
Różni się ono nieznacznie od eksportu zbiorczego.
W pierwszym oknie Źródło zwykle wybieramy obiekt, który chcemy eksportować.
W przypadku tego rysunku, wybieramy jeden z szablonów profili uprawnień w systemie.
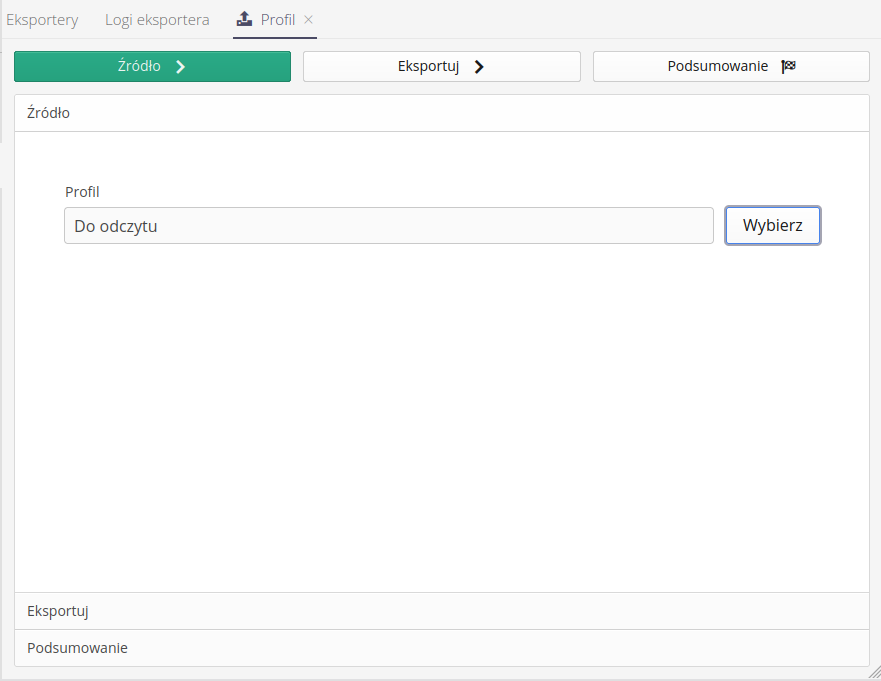
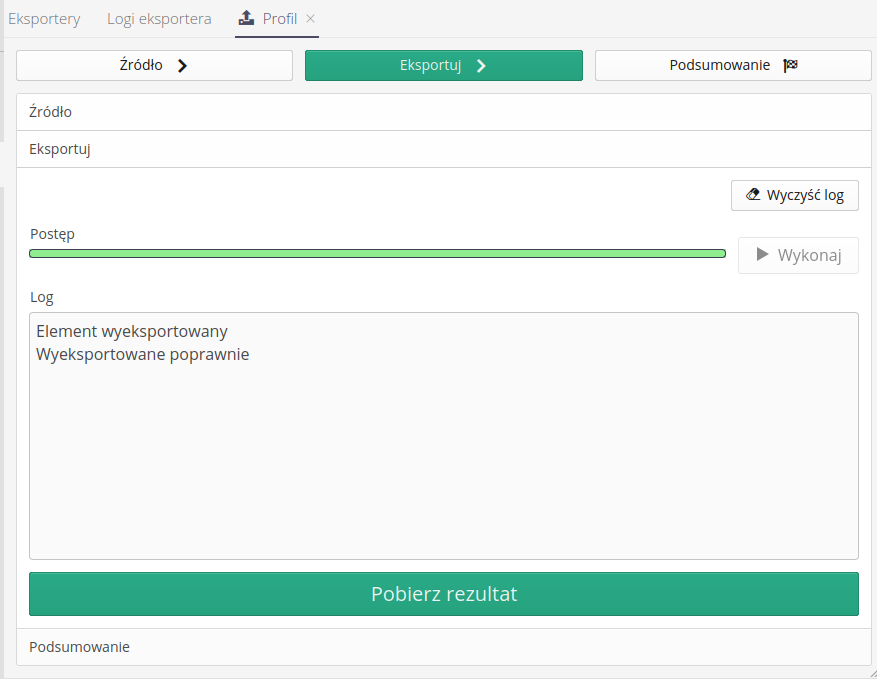
Następnie przechodzimy do procesu eksportowania.
Wykonanie tej czynności jest identyczne do procesu masowego tj. wykonujemy generację danych za pomocą przycisku Wykonaj a następnie pobieramy wygenerowany plik za pomocą akcji Pobierz rezultat.
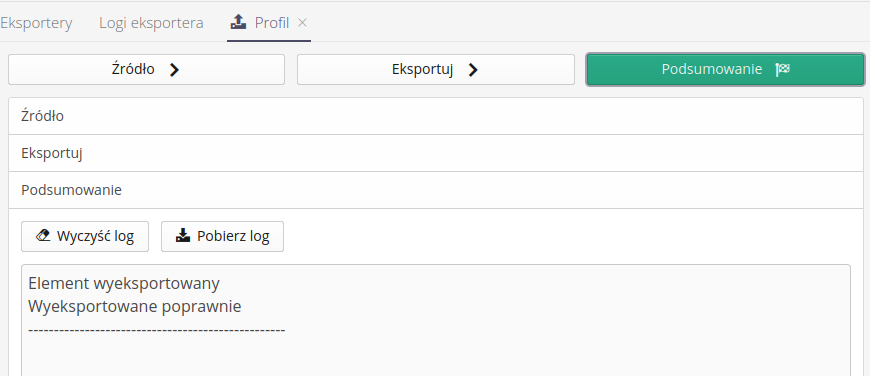
Ostatnim krokiem jest podsumowanie całego procesu i możliwość przeglądnięcia wszystkich danych powstałych w procesie eksportu.
Integracje automatyczne
System AMAGE pozwala na automatyzowanie czynności wymiany danych pomiędzy zewnętrznymi systemami IT oraz innymi źródłami danych.
Za pomocą tego mechanizmu możemy automatyzować przesyłanie informacji do/z systemu.
Aby skorzystać z tej funkcjonalności należy w sekcji konfiguracyjnej systemu otworzyć grupę Wymiana danych.
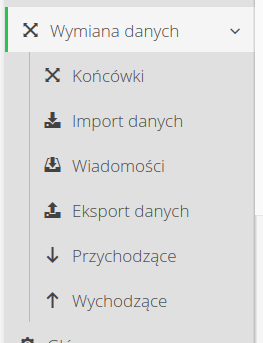
Menu zawiera zarówno już omówione mechanizmy eksportu i importu danych, ale też kilka widoków pozwalających utworzyć tzw. końcówkę integracji oraz monitorować przesyłane dane do/z systemów
Dostępne widoki:
-
Końcówki - definicja punktów i mechanizmów komunikacji
-
Wiadomości - lista wszystkich ogólnych wiadomości otrzymanych z/do zewnętrznych źródeł
-
Przychodzące - zidentyfikowane i obsługiwane wiadomości przychodzące
-
Wychodzące - wszystkie wysłane wiadomości z systemu AMAGE jako dziennik wychodzących zmian
Końcówka integracji
Końcówka integracji (ang. Endpoint) to lista zdefiniowanych w systemie źródeł/celów integracji. Mechanizm pozwala na definicję dowolnej liczby końcówek, które dostarczają dane do systemu AMAGE (tzw. przychodzące) jak i eksportujące dane (tzw. wychodzące).
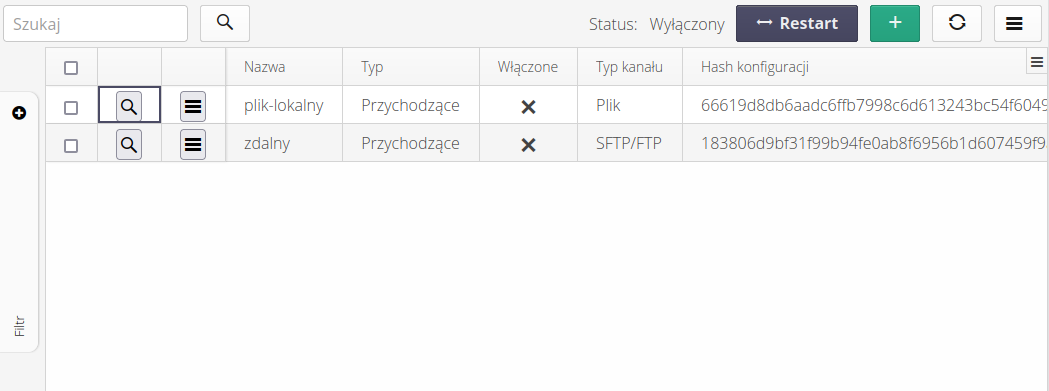
Każda z takich definicji posiada zdefiniowane źródło/cel danych. Obsługiwane przez AMAGE są źródła typu: plik lokalny (na serwerze), wiadomości email, serwer FTP/SFTP, tabele relacyjnych baz danych (SQL) oraz inne w zależności od wdrożenia.
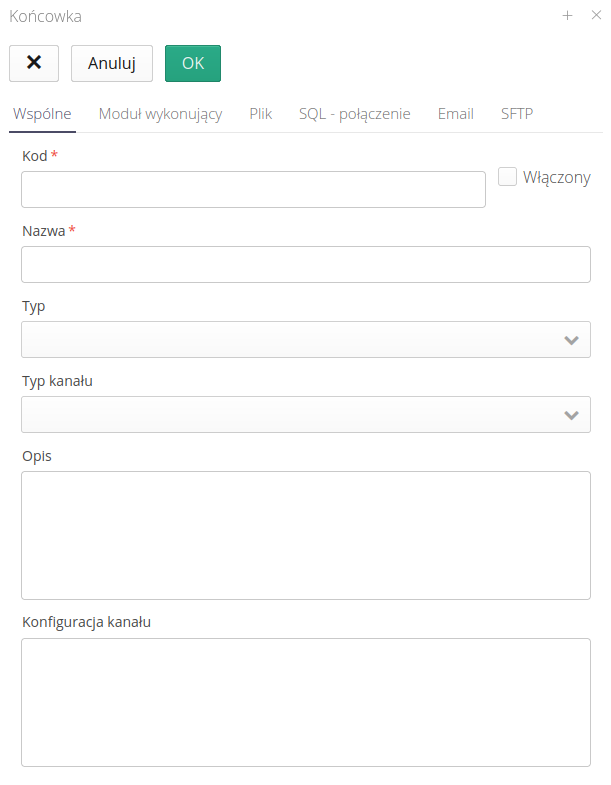
Definicja nowej końcówki dzieli się na kilka sekcji.
Dane Wspólne określają ogólny sposób obsługi i mechanizmu integracji
-
Kod/Nazwa/Opis - dane opisowe końcówki
-
Włączony - włączenie/wyłączenie z pracy danej końcówki
-
Typ - Przychodzące/Wychodzące - typ danych. Przychodzące to dane, które są źródłem wiadomości dla systemu AMAGE
-
Typ kanału - Plik, SQL, Email, SFTP - wybrany kanał komunikacji (otrzymywania) danych
-
Konfiguracja kanału - zbiorcza konfiguracja kanału komunikacyjnego - umożliwia przesyłanie/przenoszenie informacji pomiędzy instancjami.
| W zależności od wybranego kanału (przychodzący, wychodzący) formularze końcówek zmieniają widok i pokazują tylko te opcje, które są odpowiednie dla danego kierunku komunikacji. |
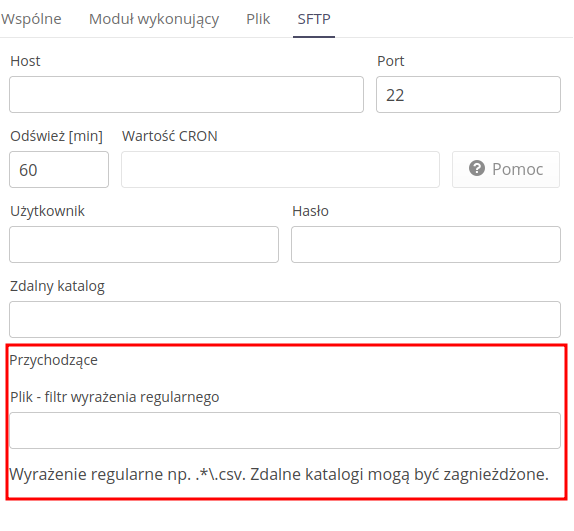
Druga zakładka definiuje źródło/cel integracji oraz umożliwia jego skonfigurowanie.
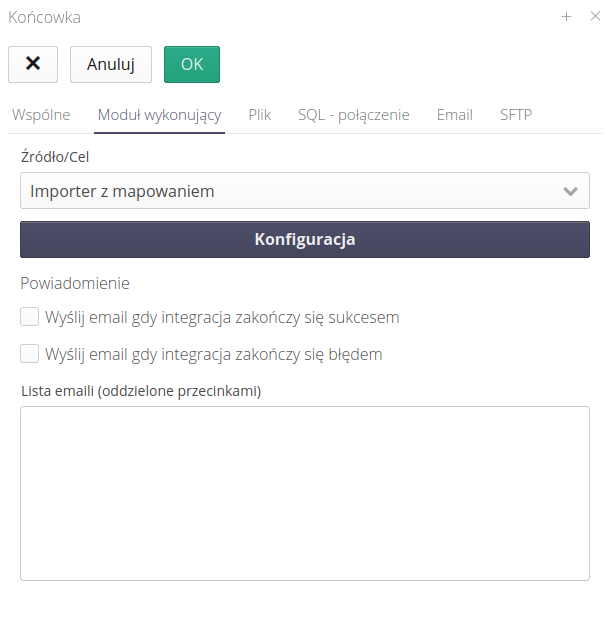
Konfiguracja i źródło określają w jaki sposób należy traktować odebrane/wysyłane pliki. Możemy skorzystać z szeregu funkcji uzależnionych od parametrów głównych systemu. Możemy na przykład wybrać jako cel danych mechanizm importu danych do systemu AMAGE oraz wskazać za pomocą jakiego szablonu mapowania będą importowane pliki, które zostaną odebrane ze zdefiniowanego kanału komunikacji.
Powiadomienia pozwalają na przesłanie informacji w przypadku poprawnej lub błędnej integracji. Wybieramy listę adresów email oraz sposób przesyłania informacji i typów zdarzeń:
-
gdy zakończy się sukcesem - wysyłamy gdy integracja zostanie wykonania poprawnie
-
gdy wystąpił błąd integracji - wysyłamy, gdy wystąpił błąd integracji
-
lista emaili - lista adresów email, które będą adresatami komunikacji
Przykładowa konfiguracja modułu wykonującego pozwala na określenie, że wykorzystujemy jako cel importowanie dostaw do systemu AMAGE i wybieramy za pomocą dolnego pola wyboru odpowiednie mapowanie, za pomocą którego będą interpretowane otrzymane pliku csv/xls.
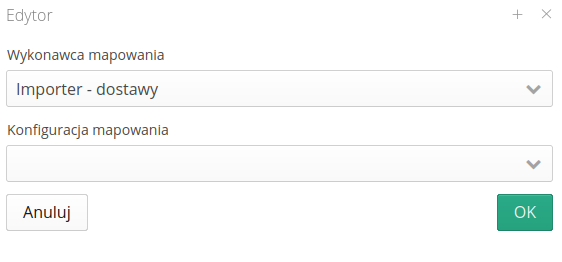
Każda końcówka ma swoją konfigurację. W zależności od tego czy wybraliśmy mechanizm importowania danych do AMAGE czy eksportowania mogą być aktywne wybrane pola z definicji danego modułu
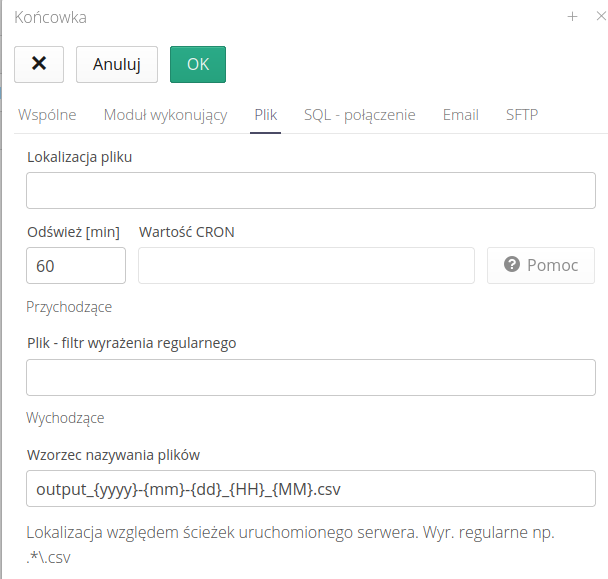
Integracja przez plik lokalnych (przesłany na serwer, na którym uruchomiony jest system AMAGE). Parametry konfiguracji
-
Lokalizacja pliku - lokalizacja pliku w lokalnym systemie np. /opt/import/data/
-
Odśwież [min] - co ile odświeżać status i szukać nowych obiektów
-
Pomoc - przycisk pomocy wskazujący sposób konfiguracji wywołań za pomocą syntaktyki CRON
-
Plik - filtr wyrażenia regularnego - dodatkowy filtr za pomocą którego możemy importować tylko wybrane pliki odpowiadające danemu wzorcowi
Wychodzące * Wzorzec nazywania plików - dla komunikacji wychodzącej określamy wzorzec nazewnictwa plików wynikowych z możliwością wykorzystania znaczników czasu.
| Podczas integracji przychodzącej pliki po integracji oryginalne dane zostają zarchiwizowane w magazynie danych. |
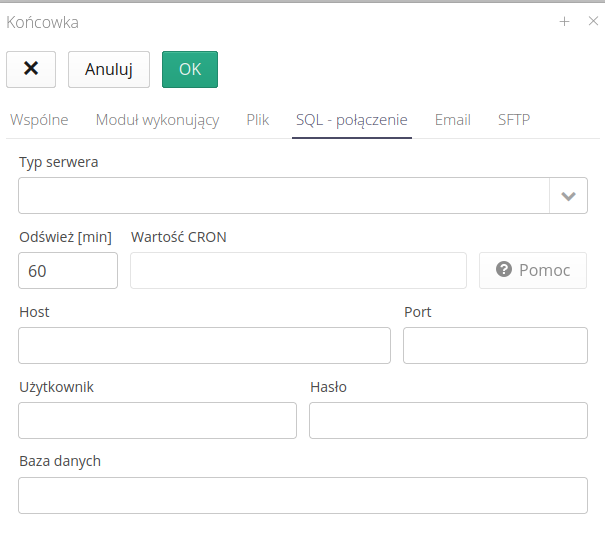
Integracja z serwerami SQL
-
Typ Serwera - typ serwera docelowego np. PostgreSQL, Microsoft SQL Server
-
Odśwież [min] - co ile odświeżać status i szukać nowych obiektów
-
Host/Port/Użytkownik/Hasło - dane dostępu do bazy danych i serwera
-
Baza danych - nazwa bazy danych
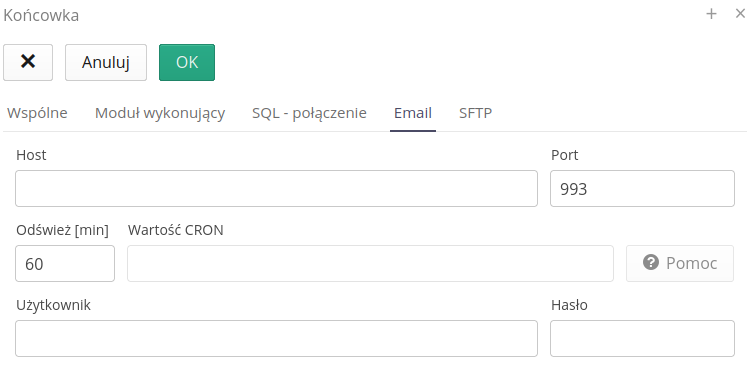
-
Host/Port - host/port serwera pocztowego
-
Odśwież [min] - co ile odświeżać status i szukać nowych obiektów
-
Użytkownik/Hasło - użytkownik i hasło do autoryzacji do skrzynki pocztowej
Dodatkowe filtry pozwalają na edycję i ograniczenie przesyłanych danych. Filtr ogranicza pocztę email na podstawie zdefiniowanych filtrów.

Przychodzące:
* Zdalny katalog - INBOX - nazwa zdalnego katalogu dla synchronizacji przez protokół IMAP * Użyj terminu LUB - pozwala na wybór jednego z podanych filtrów, co pozwala na wybór jednego z filtrów zamiast wszystkich warunków naraz * Ogranicz filtr na pole OD - akceptuj tylko emaile z określonymi adresami nadawcy * Ograniczenie odbiorcy - pozwala na ograniczenie na podstawie adresata docelowego.
W przypadku systemów pocztowych typu Google, który pozwala na dodawanie do nazwy adresu dodatkowych znaków np. + możemy wykorzystać ten filtr do określenia, że akceptujemy tylko maile z określonymi adresami nadawcy.
* Ograniczenie tematu emaila - obsługuj tylko te emaile, które mają podany wzorzec w tytule maila * Ogranicz pole OD do użytkowników i kontaktów kontrahentów - ogranicz akceptowanych nadawców tylko do listy email pochodzących od użytkowników, jak i kontaktów kontrahentów
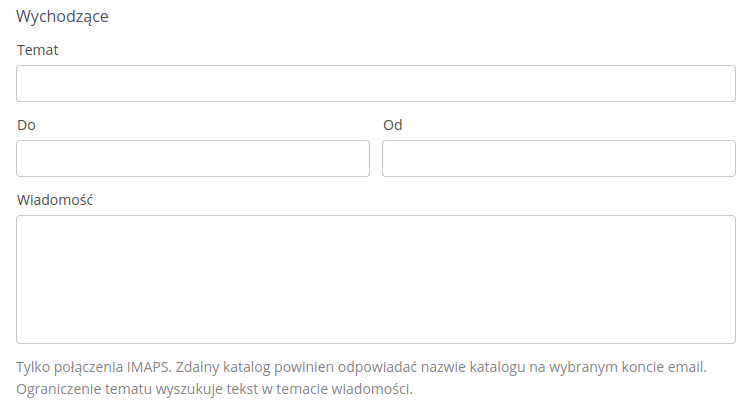
Wychodzące:
-
Temat - tytuł wiadomości email
-
Do - jw., przy definicji emaila tj. adresat wiadomości
-
Od - wskazanie od kogo pochodzi email
-
Wiadomość - pełny tekst wiadomości. Wynik eksportu zostanie dołączony do tej wiadomości email jako załącznik.
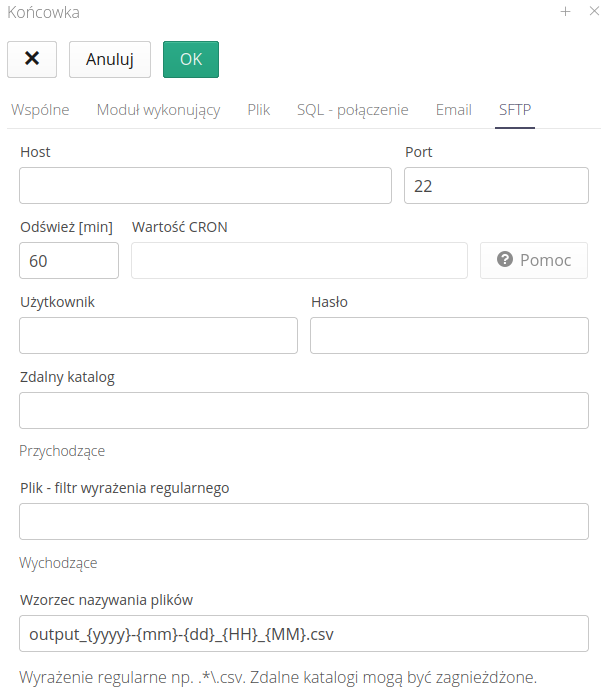
Integracja przez serwery SFTP/SCP/FTP
-
Host/Port - adres/port serwera
-
Odśwież [min] - co ile odświeżać status i szukać nowych obiektów
-
Użytkownik/Hasło - użytkownik/hasło do logowania
-
Zdalny katalog - zdalny katalog do wyszukiwania plików źródłowych
Przychodzące:
-
Plik - Filtr wyrażenia regularnego - nazwa pliku, który będzie akceptowany i importowany do systemu
Wychodzące:
-
Wzorzec nazywania plików
{yyyy},{mm},{dd},{HH},{MM}- wzorzec nazewnictwa plików eksportowanych za pomocą tego mechanizmu.
| Podczas integracji przychodzącej pliki po integracji oryginalne dane zostają zarchiwizowane w magazynie danych. |
Moduły wykonujące
Moduły wykonujące to zdefiniowane w systemie automaty, które wykorzystają dowolne połączenie (SQL, Email, Plik, FTP) i wykonają na pozyskanych z tego kanału danych operacje. W zależności od kanału i danych możemy wykorzystać zestaw funkcji i czynności, które wprowadzą dane z zewnętrznego źródła do systemu AMAGE.
SQL - dowolne zapytanie INSERT (eksport)
Moduł pozwala na wykonanie dowolnych operacji na zewnętrznym systemie baz danych. Pozwala to na wykonanie jednorazowe/okresowe zapytań o stałym charakterze np. konfiguracyjnym.
W oknie definicji danych wprowadzamy dowolny zestaw zapytań SQL, które zmodyfikują zewnętrzny system.

SQL - parametry/dane produkcyjne (import/eksport)
Moduł pozwala dla danych importowanych przenieść je do parametrów zasobów lub do danych produkcyjnych. Dla przykładu systemy zewnętrzne mogą dostarczać informacji w tabelach wymiany. Dane te powinniśmy odczytać a następnie wprowadzić jako wartości parametru w zasobie (wraz z historią) lub wprowadzić do dowolnego parametru produkcyjnego.
Po włączeniu konfiguracji otrzymujemy dwie zakładki. Jedna dotycząca operacji zapytania SQL oraz czynności do wykonania po zakończeniu importu - również zapytania SQL.
W takim przypadku pierwsze zapytanie może dotyczyć pobrania danych z dowolnych tabel zdalnego systemu SQL i uporządkowaniu ich w kolumny o odpowiednich nazwach. Natomiast zapytanie kończące może służyć do usunięcia już odczytanych rekordów ze zdalnej tabeli wymiany.
W przypadku zdalnych tabel, których nie możemy czyścić, możemy skorzystać z funkcjonalności zapamiętania w systemie AMAGE jakiegoś pola i traktować go jako identyfikator przy kolejnych zapytaniach. Dla przykładu kwerenda SQL oraz pole może wyglądać jak na rysunku poniżej.
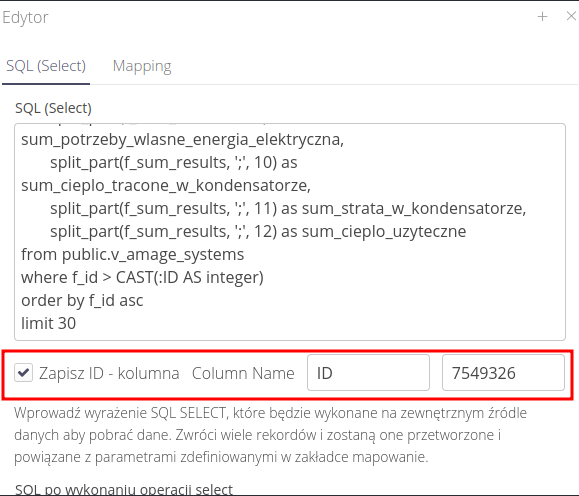
W zapytaniu wykorzystujemy pole ID do ograniczenia danych tylko do tych, które są nowsze niż ostatnio przez nas przetworzone. Po zakończeniu zapytania system automatycznie zapisze ostatni ID rekordu przetworzonego.
| W początkowym przypadku należy ustawić pole na wybraną wartość np. 0 |
Druga sekcja pozwala na zdefiniowanie mapowania tj. docelowego miejsca, do którego trafią dane. Robimy to poprzez dodanie kolejnych rekordów mapowania. Mapowanie łączy kolumny z wyniku zapytania SQL z docelowym miejscem na zapisanie danych.
Konfiguracja pozwala na określenie:
-
Nazwy kolumny, która zawiera datę i czas rejestracji danych
-
Nazwy kolumny, które zawiera wartość do pobrania
-
Możliwość określenia równania matematycznego do przetworzenia wartości np. w przypadku gdy chcemy pobrane dane pomnożyć przez 1000
-
Opis mapowania
-
Docelowego miejsca, w którym znajdą się dane. Do wyboru są parametry zasobów oraz dana produkcyjna
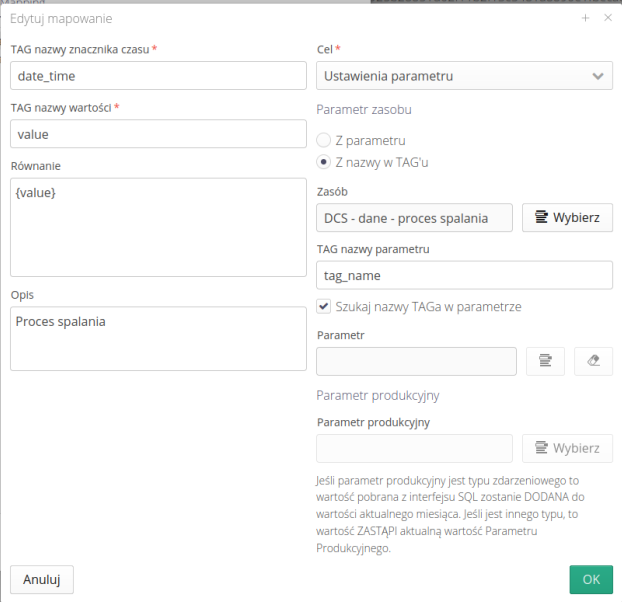
W przypadku danej produkcyjnej określamy konkretną daną do zapisu pobranej wartości.
W przypadku parametru zasobu mamy możliwość albo wskazania konkretnego parametru albo wskazania, która kolumna z wyniku zapytania SQL przechowuje nazwę parametru (ograniczonego do wybranego zasobu).
Pozwala to na dynamiczne wpisanie danych do kilku parametrów na podstawie danych w systemie źródłowym.
Za pomocą opcji Szukaj nazwy TAGa w parametrze pozwalamy na wyszukanie nazwy w polu nazwa/opis danego parametru bez konieczności dokładnego porównania tj. pole np. numer KKS mogą być zawarte w dłuższym opisie parametru a system powiąże je również poprawnie.
| Dla integracji wychodzącej tj. przesyłającej dane do systemu pojawia się inne pole z zapytaniem typu INSERT. |
W tym miejscu możemy wprowadzić zapytanie, które zapisze wszystkie wartości zdefiniowane w mapowaniu np. aktualną wartość parametru w zdalnym systemie SQL.
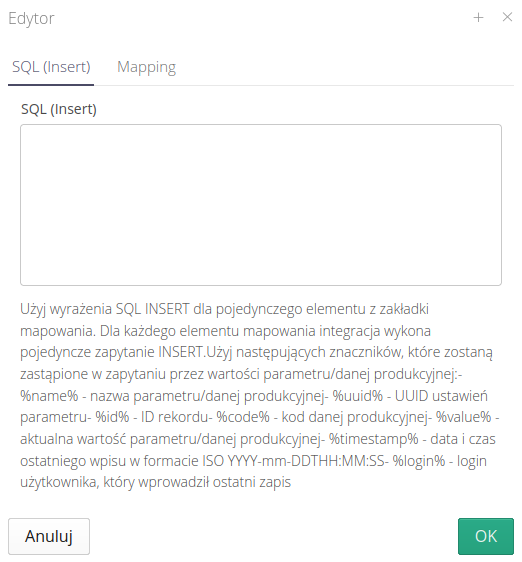
W oknie znajduje się informacja jakich znaczników użyć, aby w nich miejscu pojawiły się odpowiednie wartości danej źródłowej - wartość, czas, użytkownik itp.
Importer z mapowaniem
Moduł pozwala wywołać import danych z pliku CSV/XLS np. pobranego z serwera FTP. Wyznaczamy funkcję importującą oraz mapowanie parametrów.
| Należy odnieść się do dokumentacji importerów w celu konfiguracji mapowania danych. |
Eksporter z mapowaniem
Moduł pozwala wywołać eksporter danych zgodnie z wybranym mapowaniem i wysłać wynikowy plik xls/csv do zewnętrznego kanału (FTP/Email)
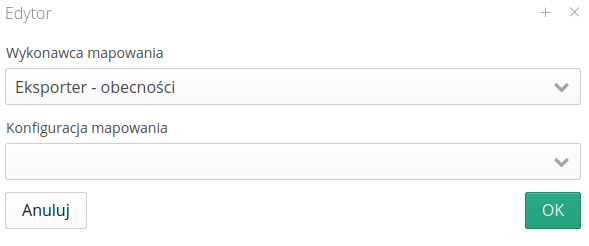
| Należy odnieść się do dokumentacji eksporterów w celu konfiguracji mapowania danych. |
EDI - Dostawa - CSV - Dzierżawy/PERI
Moduł importowania danych w formacie PERI CSV.
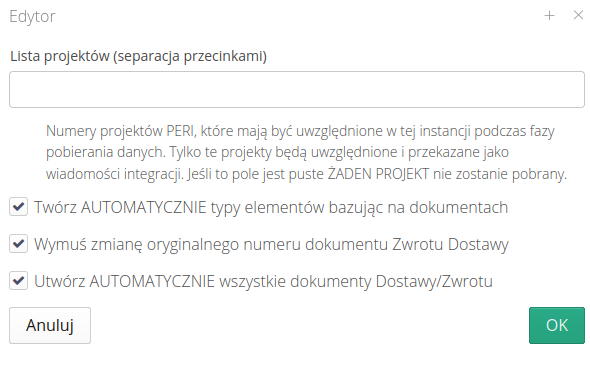
EDI - Dostawa - CSV - Dzierżawy/ULMA
Moduł importowania danych w formacie ULMA CSV.
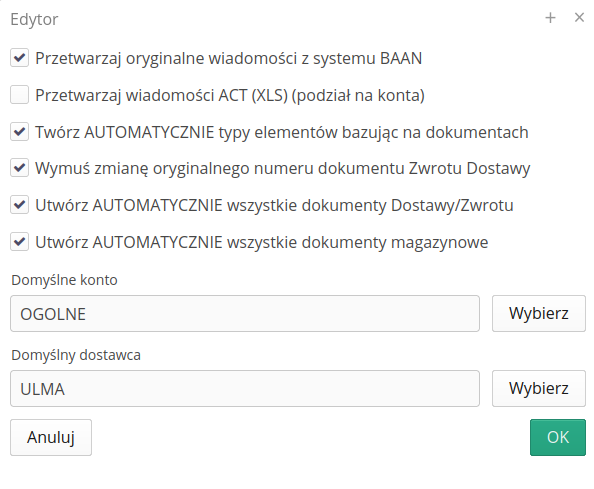
EDI - Dostawa - UBL - Dzierżawy/PERI
Moduł importowania danych w formacie PERI UBL

Integracje - Palisander - automatyczna integracja dokumentów pz/wz
Dla systemu dzierżaw i ich rozliczania dodano możliwość importu danych w formacie EDI pochodzących z firmy Palisander. Dane dostaw i zwrotów automatycznie integrowane są w systemie.
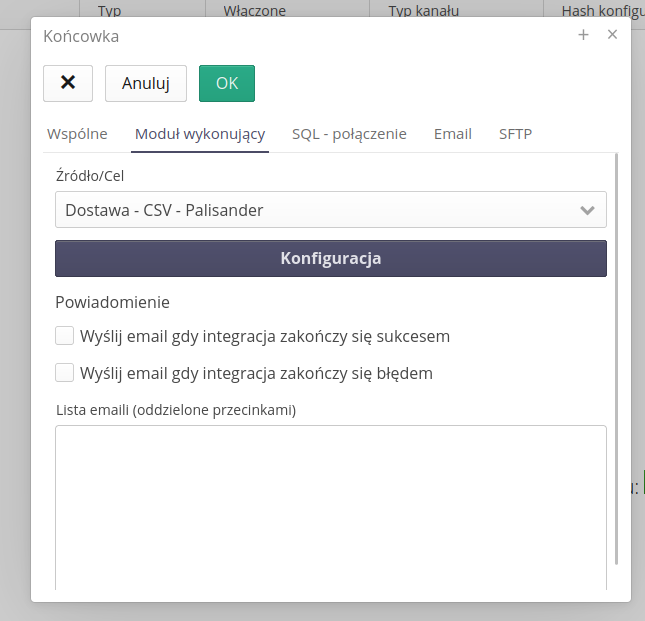
Eksporter danych - końcówka generacji raportu z zakładki
Dla systemów automatycznej integracji dodano możliwość wygenerowania raportu z wybranego szablonu raportu i zdefiniowanej zakładki (definicji danych/filtrów).
Automat po wybraniu opcji Generator raportów w trakcie jego wywołania wybierze raport z określonym zakresem danych i wygeneruje raport w wybranym formacie XLS/PDF i wykorzysta go w zdefiniowanej końcówce danych i wyśle jako załącznik emailem lub prześle na określony serwer SFTP.
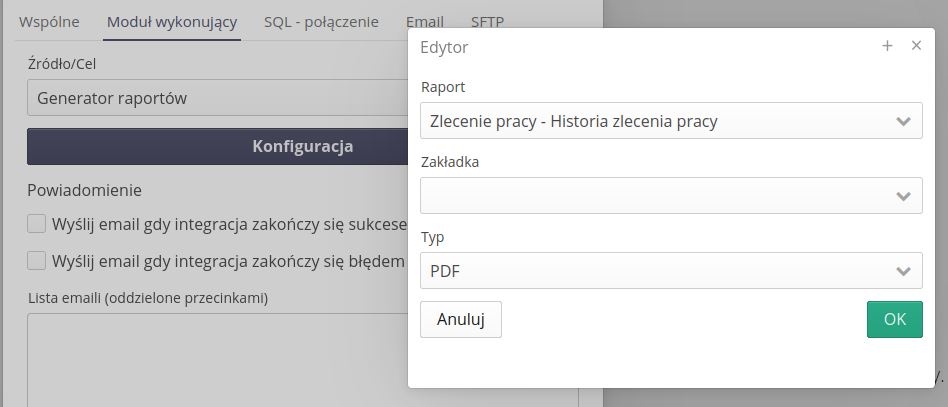
Zawartość emaila
Odczytanie zawartości emaila i zapisanie w systemie. Nie wymaga konfiguracji. Rozbudowano mechanizm integracji o dodatkowy transfer/odbieranie plików z adresów email. Za pomocą tego mechanizmu mamy możliwość określenia, jakie dokumenty email będą pobierane z serwera (od adresata, z tytułem, w lokalizacji). Maile te zostają wczytane do systemu do modułu integracji i cała ich zawartość udostępniona w systemie (załączniki, treść).
Pozwala to na przechowywanie w systemie również korespondencji email dotyczącej danego projektu. Wystarczy przesłać email z określonym filtrem na adres email docelowy, a system automatycznie zajmie się wszystkim.
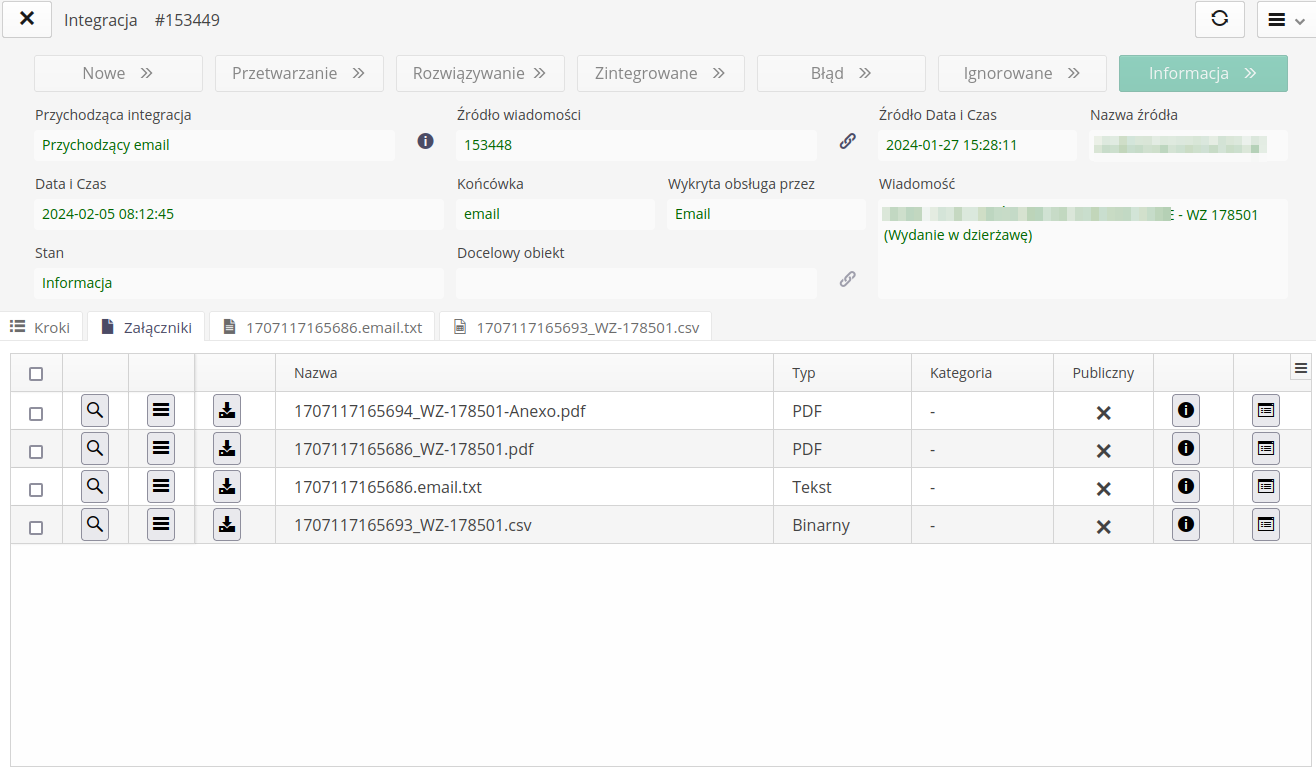
Logowanie operacji i podgląd
Wszystkie informacje dotyczące automatów integracji są zapisywane w logach systemu.
Możemy przeglądać szczegółowe informacje o operacjach, które zostały wykonane w systemie.
W sekcji konfiguracji w menu Podgląd logów mamy dostęp do wszystkich operacji, które zostały wykonane w systemie.
Wybierając logger integracje mamy możliwość przeglądania szczegółowych działań wykonywanych przez te automaty.
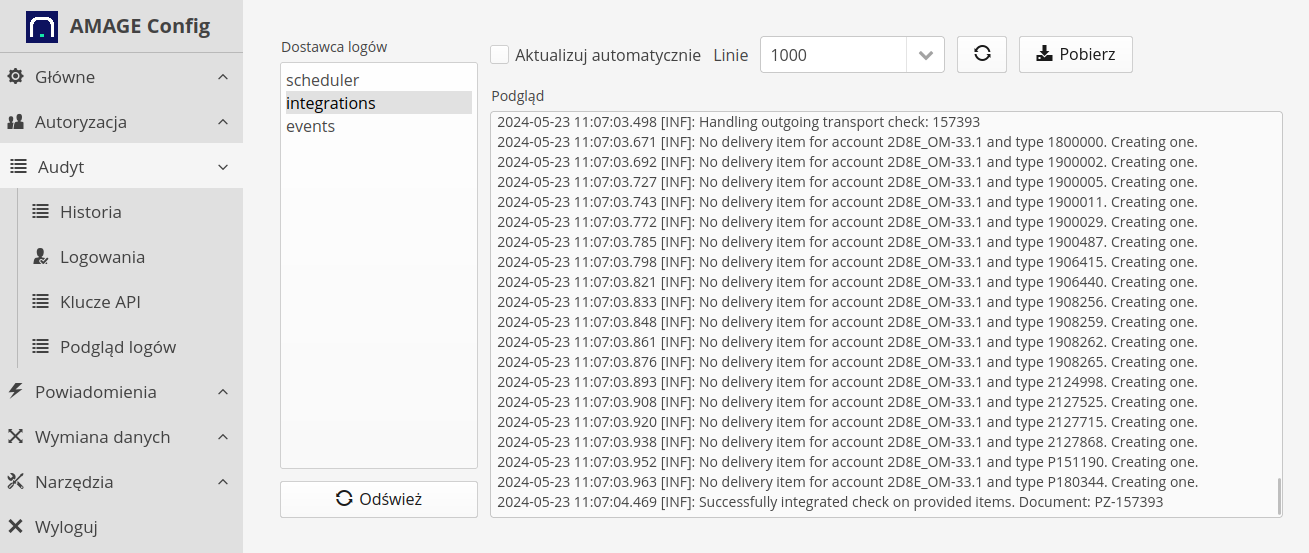
Wiadomości
Lista wiadomości zawiera wszystkie wiadomości odebrane przez jakąkolwiek końcówkę danych. Mechanizm obsługi danych pochodzących z zewnętrznych źródeł jest następujący:
-
Odbieramy pliki/obiekty zgodnie ze zdefiniowanym wzorcem w definicji końcówki
-
Transferujemy obiekty do systemu AMAGE, zapisujemy w lokalnych magazynach i tworzymy obiekt
Wiadomość -
Przeglądamy konfigurację końcówki i sprawdzamy, czy otrzymany obiekt może być przetworzony przez zdefiniowany moduł odbiorczy (np. pobraliśmy przez przypadek nie ten typ pliku, pliki są uszkodzone, pliki nie zawierają istotnych danych).
-
Jeśli poprawnie zidentyfikujemy pliki, to tworzone są odpowiednie wiadomości przychodzące i tam przekazywana jest procedura obsługi.
-
UWAGA: Jeśli obiekt nie jest możliwy do przetworzenia, zostaje on jedynie na poziomie widoku wiadomości.
Lista wiadomości zawiera właśnie wszystkie tego typu komunikaty otrzymane z zewnętrznych systemów.
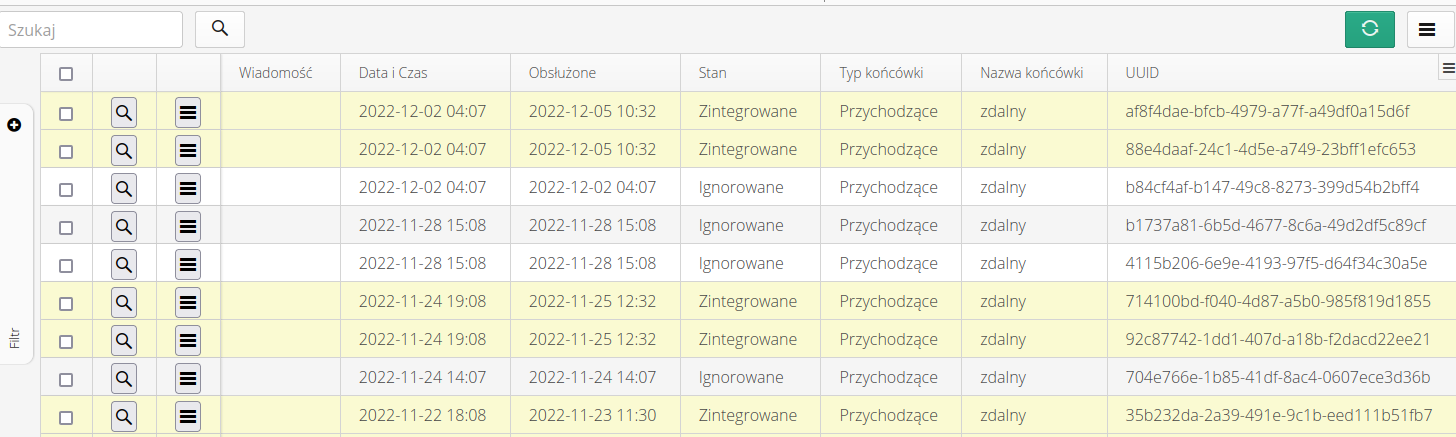
Za pomocą filtrów wiadomości możemy ograniczyć dane i mieć możliwość analizy wszystkich rekordów zbiorczo.
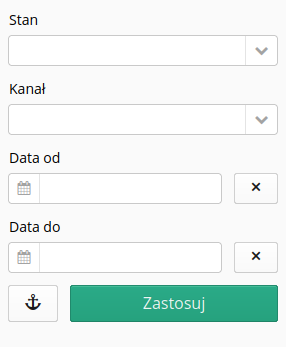
Szczegóły wiadomości zawierają wszystkie zidentyfikowane właściwości tej wiadomości oraz informacje o powiązanych danych przychodzących/wychodzących
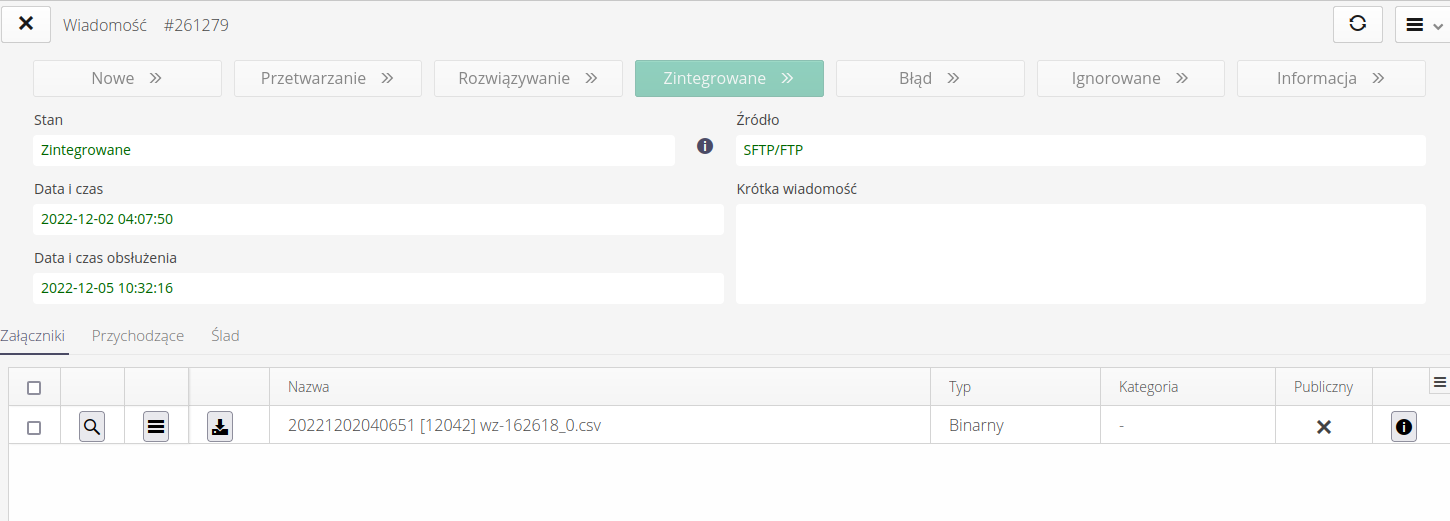
Wiadomość może być w stanach:
-
Nowe - nowa wiadomość, dopiero co odebrana z określonej końcówki
-
Przetwarzanie - wiadomość w trakcie przetwarzania
-
Rozwiązywanie - wiadomość (i jej efekt) wymagają podjęcia decyzji przez operatora
-
Zintegrowane - wiadomość zintegrowana w głównych tabelach systemu
-
Błąd - błąd integracji
-
Ignorowane - wiadomość jawnie ignorowana np. wysłana powtórnie przez przypadek
-
Informacja - wiadomość informacyjna. Poprawna w składni, ale na dany moment nie obsługiwana przez odpowiednie mechanizmy.
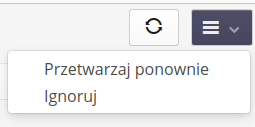
Menu kontekstowe każdej wiadomości pozwala na uruchomienie ponowne przetwarzania (np. gdy zostanie poprawiony błąd, który spowodował wcześniejsze zatrzymanie integracji) lub ignorowanie tej wiadomości
-
Przetwarzaj ponownie - ponów przetwarzanie od początku
-
Ignoruj - zignoruj wiadomość i jej nie przetwarzaj.
Dla przykładu w wiadomości przychodzącej do systemu AMAGE pojawia się poprawnie zidentyfikowany plik dotyczący dostawy i utworzona jest wiadomość przychodząca a następnie dalej przetwarzana.

Przychodzące integracje
Wiadomości przychodzące to wszystkie wiadomości, które zostały poprawnie zidentyfikowane jako możliwe do przetworzenia. Lista wszystkich wiadomości pozwala na przegląd danych i dostęp do wszystkich informacji tam dostępnych
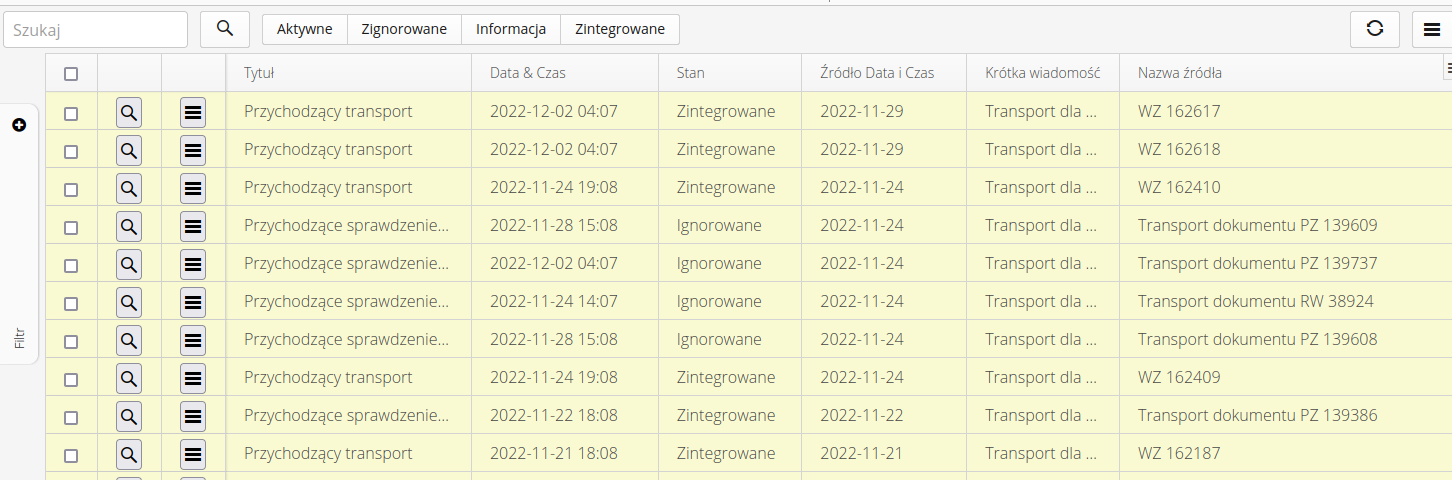
W widoku możemy za pomocą podstawowych filtrów wyświetlić tylko główne przychodzące wiadomości, które nas interesują.

Dostępne stany filtrów:
-
Wszystkie - wszystkie integracje w jednym widoku
-
Aktywne - tylko aktywne wiadomości tj. takie które są w tym momencie przetwarzane przez użytkownika lub takie które czekają na decyzje
-
Zignorowane - wiadomości zignorowane (albo przez system albo przez użytkownika)
-
Informacja - wiadomości traktowane jako informacyjne tj. nie wpływające na strukturę systemu
-
Zintegrowane - wiadomości już zintegrowane do systemu
Po wybraniu dowolnej wiadomości przychodzącej przechodzimy do widoku szczegółów integracji. Górna część zawiera podstawowe informacje o integracji, danych i ekstrakt z informacji zawartych w danych źródłowych.
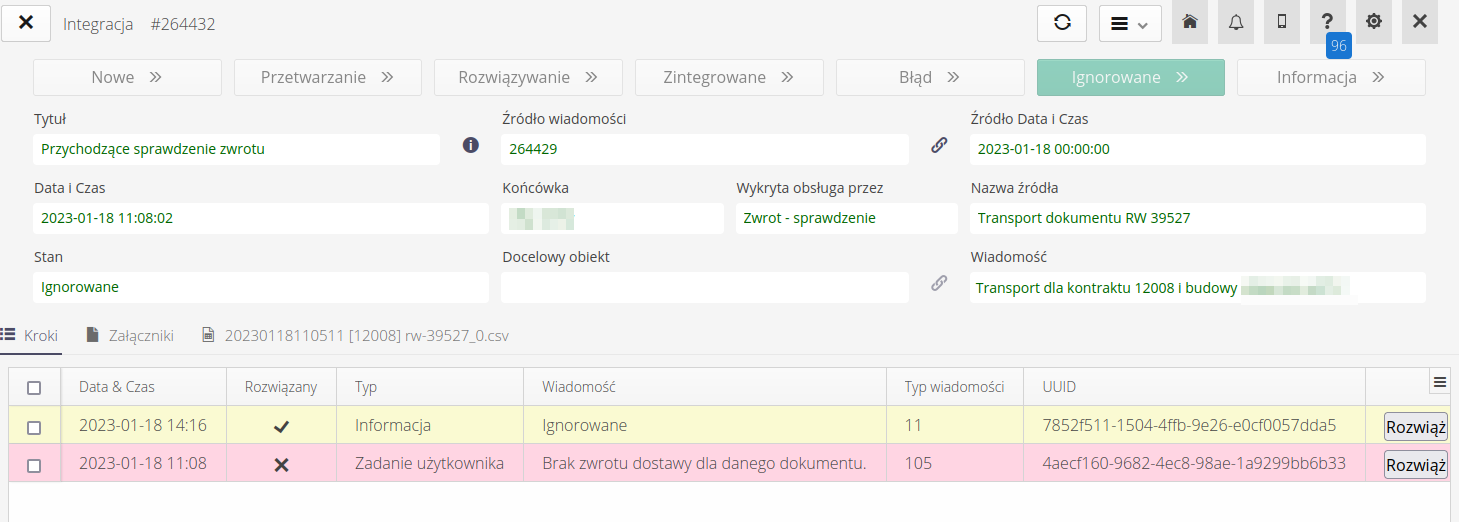
Panel załączniki zawiera wszystkie dane w formie plików dołączone do wiadomości. Są to pliki źródłowe, pliki towarzyszące (np. PDF) lub podobne. Z tego miejsca zawsze można pobrać plik do dalszej analizy.

Jeśli system potrafi zinterpretować i wyświetlić zawartość plików, to pojawia się dodatkowa zakładka dotycząca zawartości plików. Tutaj wyświetlamy zawartość pliku CSV i treść tego dokumentu (w tym przypadku dokumentu dostawy).

System automatycznie wykrywa formatowanie separatorów w pliku CSV i odpowiedni dzieli dane na kolumny. W przypadku błędów w pliku CSV system zwraca informacje o błędach.
W widoku szczegółowym wiadomości mamy możliwość uruchomienia ponownego przetwarzania wiadomości (gdy z jakiegoś powodu chcemy powtórnie ją uruchomić), zresetować kroki integracji lub oznaczyć wiadomość jako ignorowaną i nie zajmować się nią więcej.
Każda wiadomość w dolnej części posiada dodatkową tabelę z krokami integracji. Kroki integracji to poszczególne etapy przetwarzania takiej wiadomości. Dla dokumentów dostaw mogą to być wyszukanie w systemie odpowiednich magazynów docelowych, dostawcy, asortymentu, sparowanie i utworzenie zamówienia itp. Każdy z takich istotnych kroków pojawia się jako kolejny krok.
Niekiedy system nie potrafi samodzielnie rozwiązać danego problemu np. podano w dokumencie numer konta rozliczeniowego, którego nie ma w systemie. W takim przypadku integracja zatrzymuje się na tym kroku i prosi nadzorcę o podjęcie decyzji.
W każdej linii posiadamy również przyciski:
-
Rozwiąż - przechodzi do okna dialogowego rozwiązywania problemów integracji
-
Historia - pokazuje historię tego kroku - kto i kiedy go rozwiązał i jakie podał parametry
-
Usuń - usunięcie danego kroku
Po wybraniu akcji rozwiązania dowolnego problemu, system przedstawia to w formie okna dialogowego. W tym przypadku do dokumentu dostawy nie utworzono wcześniej dokumentu zamówienia. Za pomocą tego okna możemy wskazać zamówienie, które powinno być powiązane z daną dostawą. Po zatwierdzeniu tych danych system przechodzi do kolejnych kroków i jeśli nie napotyka kolejnych problemów automatycznie dalej przeprowadza integrację.
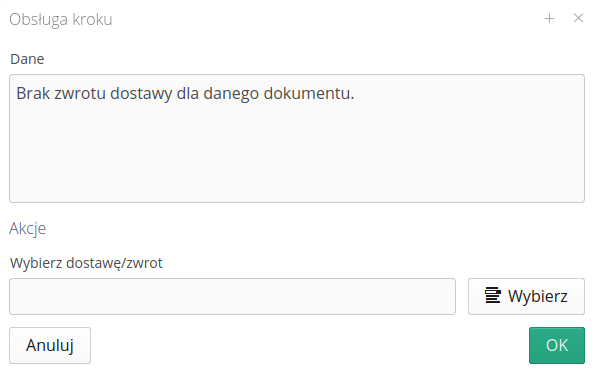
| W zależności od typu problemu, obiektu i danych okno dialogowe może zawierać inne pytania/interfejs użytkownika. |
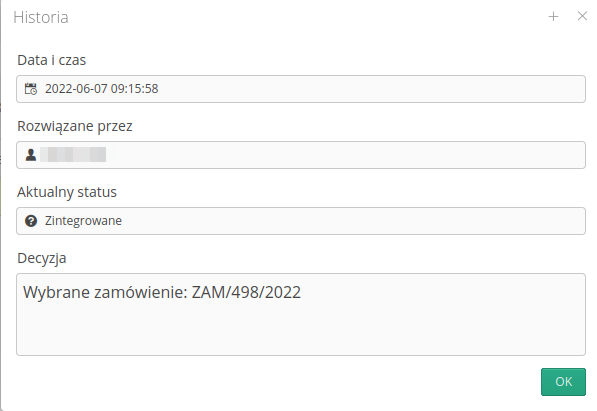
Po wybraniu przycisku Historia wyświetlamy informacje o sposobie rozwiązania takiego problemu oraz osobie, która podjęła taką decyzję.
Po poprawnej integracji system automatycznie łączy dokument integracji z docelowym dokumentem - w tym przypadku dokumentem dostawy.
Możemy szybko przejść do tego wynikowego dokumentu za pomocą pola Docelowy obiekt i akcji nawigacji znajdującej się przy nim.
Po zakończeniu integracji stan wiadomości zmienia się odpowiednio do wyniku integracji.
Wychodzące integracje
Wiadomości wychodzące zawierają wszystkie informacje dotyczące danych, które są wysyłane z systemu AMAGE do zewnętrznych źródeł. Widok główny zawiera w formie tabelarycznej informacje o wysłanych wiadomościach, ich docelowym adresie/końcówce danych oraz terminie wykonania takiej integracji.

Za pomocą dodatkowego filtru bocznego mamy możliwość ograniczenia widoku i wyfiltrowania danych odpowiednich do danego zakresu dat lub statusu.
Środowiska BIM/CDE
System AMAGE ma możliwości integracji ze środowiskami CDE (Common Data Environment) powstałymi do wsparcia procesów BIM. Za pomocą tych integracji mamy możliwość dostępu i wizualizacji modeli IFC/3D projektowanych inwestycji oraz dostępu do danych technicznych typu biblioteki i dokumentacja. AMAGE pozwala na dostęp do różnych środowisk CDE w zależności od systemu wykorzystywanego przez klienta. Pierwszym systemem jest środowisko firmy Catenda (BIM Sync/Catenda Hub) i na jego przykładzie obejmiemy tą dokumentację.
Aby moduł CDE był dostępny dla użytkowników należy go włączyć we flagach konfiguracyjnych systemu w sekcji Integracje.
|
Po poprawnej autoryzacji i połączeniu systemów (zobacz jeden z dostępnych samouczków jak to zrobić w pełni) otrzymujemy dwukierunkowe połączenie i możliwość interakcji z danymi ze środowiska bezpośrednio w systemie AMAGE.
Dostęp do przeglądarki środowiska CDE jest możliwy poprzez menu główne w sekcji Integracje.
Wybieramy akcję BIM/CDE.

Po załadowaniu widoku mamy możliwość dostępu do:
-
Modeli - modele 3D IFC z wbudowaną kontekstową przeglądarką i importem danych do systemu AMAGE
-
Dokumentów - lista bibliotek i dokumentów dostępnych w środowisku CDE
-
Model 3D - model całego projektu i przeglądarka danych
Po wybraniu modeli 3D otrzymujemy w jednej części listę wszystkich modeli IFC znajdujących się w środowisku CDE. Po wybraniu (zaznaczeniu) dowolnego w prawej części okna inicjalizuje się przeglądarka modeli 3D. Możemy w niej nawigować z wykorzystaniem myszki.
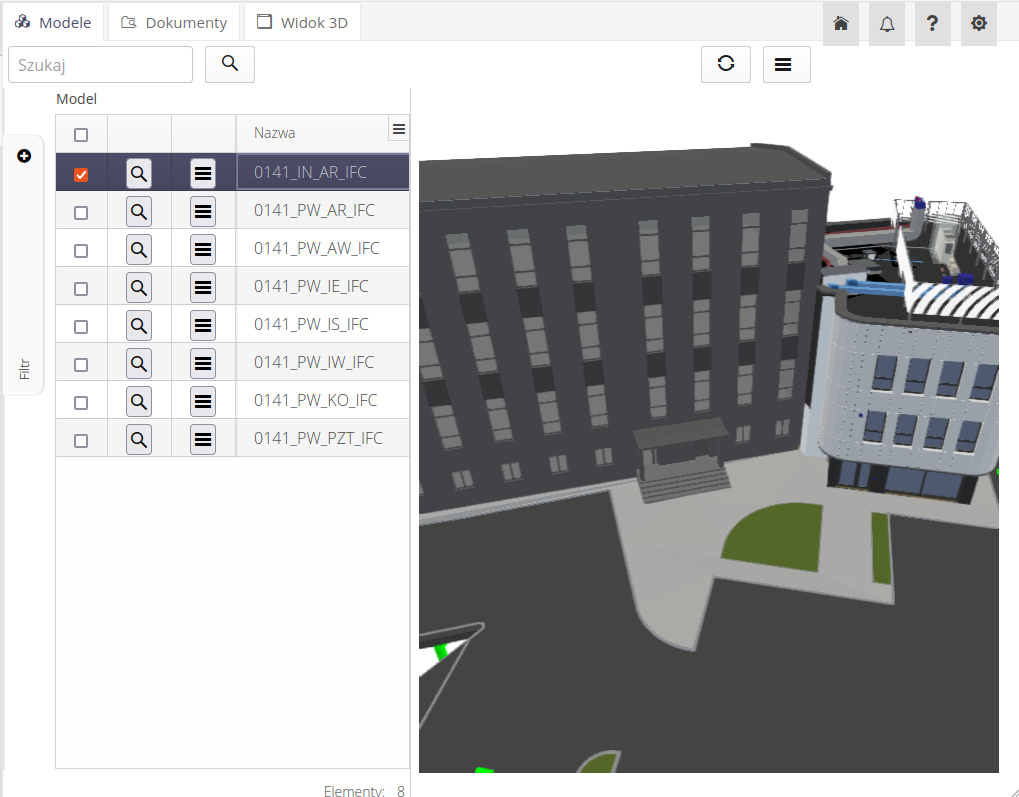
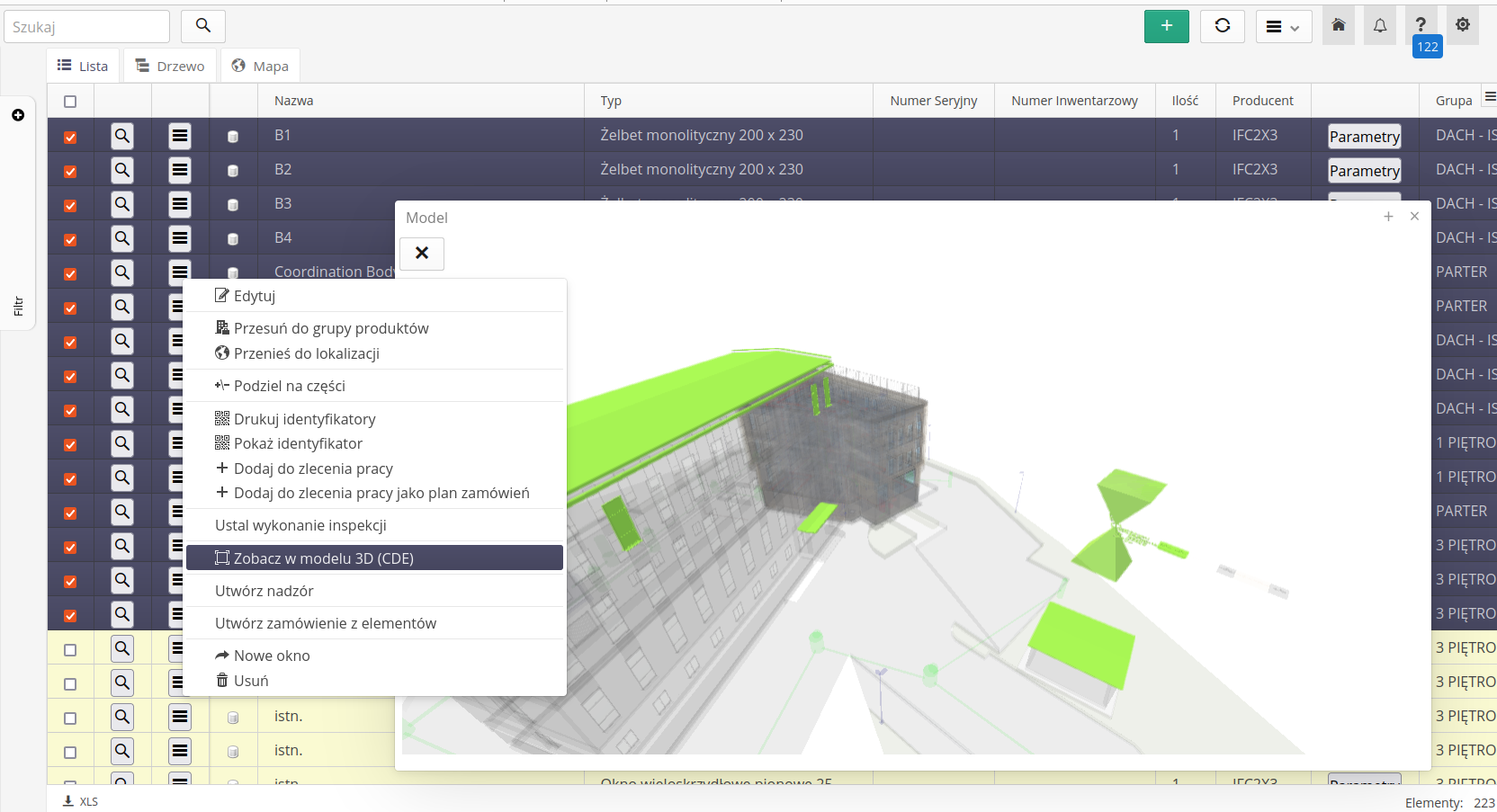
Dla każdego modelu dostępne jest menu kontekstowe.
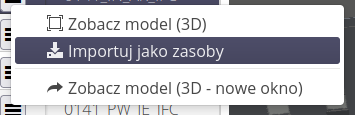
Pozwala ono na:
-
Podglądzie danego modelu w widoku 3D
-
Wywołania importera danych z formatu IFC do zasobów w systemie AMAGE
-
Otwarcia środowiska CDE w nowym oknie przeglądarki
-
Otwarcia przeglądarki danego modelu w nowym oknie
Wybranie przeglądarki dokumentów pozwala nawigować po wszystkich bibliotekach w środowisku CDE. Lista bibliotek pozwala na wybranie dowolnej biblioteki w środowisku i jej przeglądanie. Przyciski w tej samej linii pozwalają na przejście do głównego katalogu (root) danej biblioteki oraz przejście na poziom wyżej w przypadku nawigacji po folderach danej biblioteki.
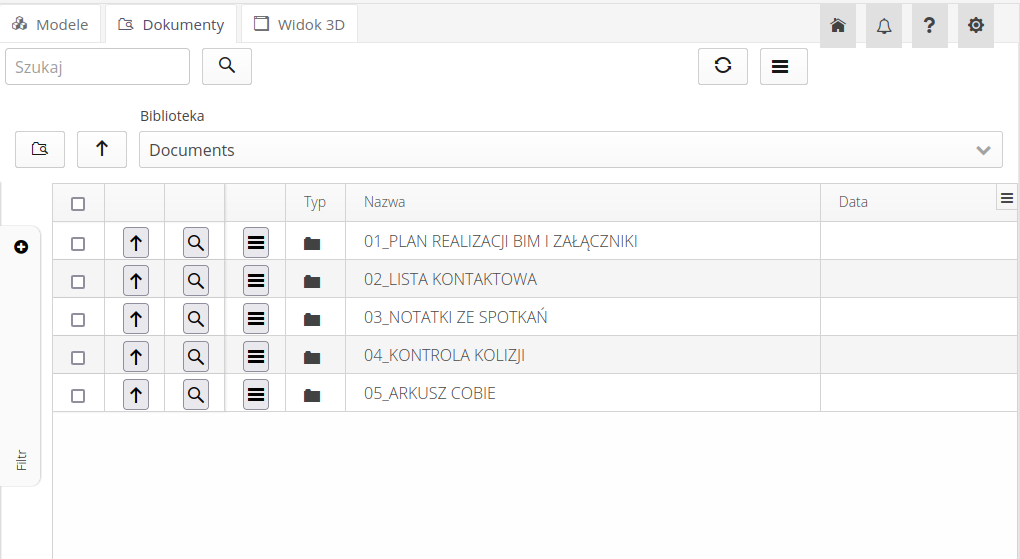
Każda linia pokazuje albo folder albo określony dokument. Za pomocą przycisków możemy przejść do folderu nadrzędnego, wywołać przeglądarkę dokumentów PDF lub wywołać menu kontekstowe.
W menu kontekstowym mamy możliwość podglądu pliku, pobrania go na dysk lokalny, dołączenia wybranych dokumentów do zasobu/typu w systemie AMAGE lub otwarcia dokumentu bezpośrednio w środowisku CDE.
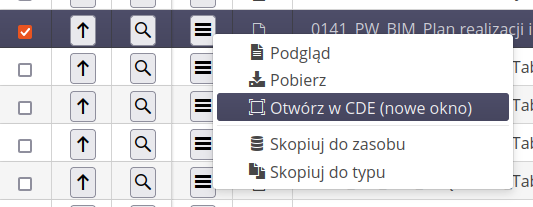
Podłączenie dokumentów spowoduje pobranie ich ze środowiska CDE i dołączenie jako załączniki do wybranego zasobu/typu. W taki sposób możemy przenosić dokumentację typu karty katalogowe i informacje techniczne.
Po wybraniu przeglądarki Widok 3D system ładuje wszystkie modele dostępne w środowisku CDE i wizualizuje je w jednym widoku.
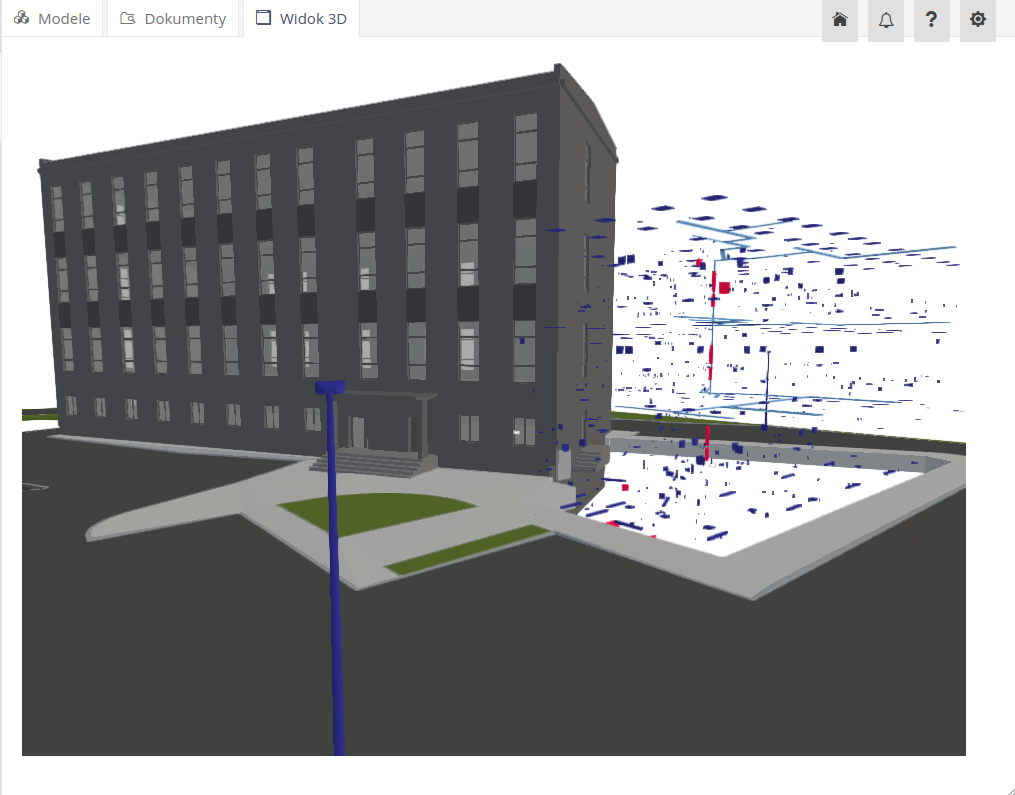
System pozwala na wyświetlenie wszystkich zasobów systemu w kontekście modelu 3D. Za pomocą dedykowanej akcji w liście zasobów mamy możliwość wyświetlenia wybranych elementów na modelu. Model po załadowaniu wszystkie nieistotne elementy oznacza jako przeźroczyste a podświetla i zaznacza wszystkie wybrane obiekty.
| Do poprawnego działania wymagane jest posiadanie dla każdego takiego zasobu zdefiniowanego parametru GlobalId podczas importu danych czy to z modelu IFC czy z innych źródeł. |
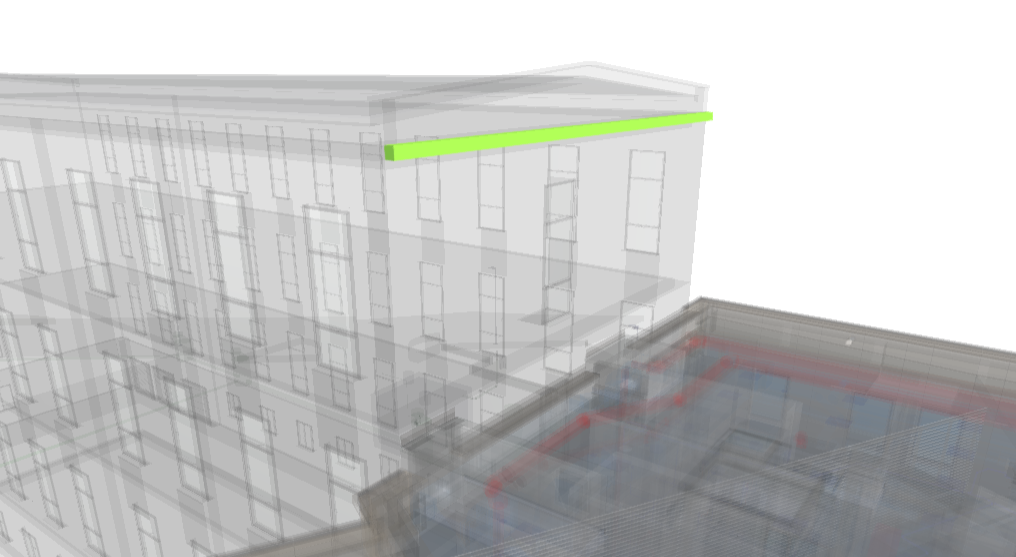
Pojedynczy obiekt z podglądem elementu.
Konfiguracja środowiska CDE
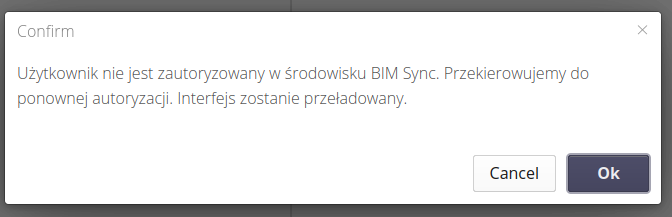
W przypadku, gdy autoryzacja dostępu do systemu CDE wygaśnie pojawi się komunikat jak niżej oraz po zatwierdzeniu system automatycznie skontaktuje się ze środowiskiem CDE i przeprowadzi ponowną autoryzację. Po powrocie interfejs zostanie automatycznie przeładowany ponownie.
Aby skonfigurować środowisko (pierwszy raz lub zmienić konfigurację) przechodzimy do sekcji konfiguracyjnej i wybieramy akcję z menu Dodatki o nazwie BIM CDE.
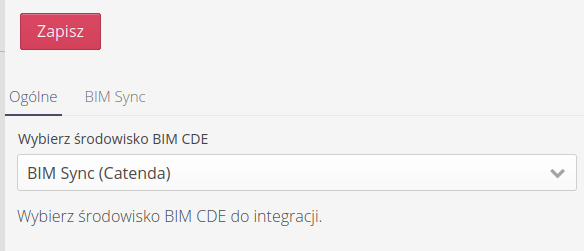
W pierwszej zakładce wybieramy z jakim środowiskiem CDE zamierzamy się połączyć.
W zakładkach określonego środowiska CDE mamy możliwość ustawienia danych połączenia i wstępnej autoryzacji lub wykonania innych czynności specyficznych dla danego środowiska.
Dla przykładu środowisko Catenda Hub/BIMSync pozwala na wpisanie danych autoryzujących pozyskanych z tego środowiska (kod autoryzujący itp.).
Jako element końcowy dla pola Redirect URI podajemy ścieżkę naszej instancji rozbudowaną o adres /integrations/auth-bimsync.
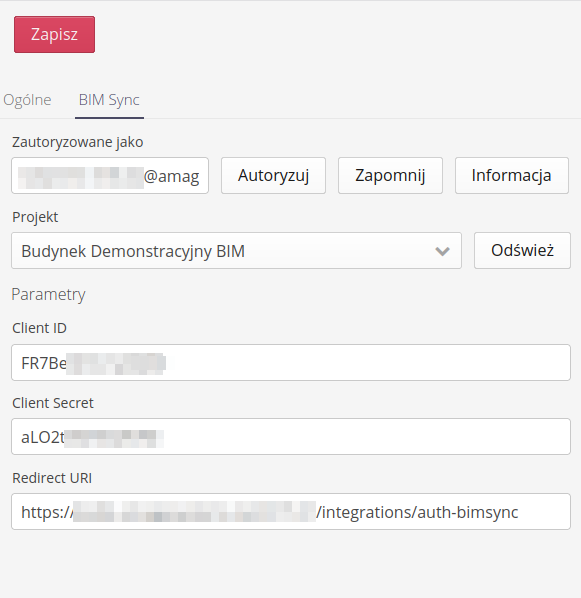
W przypadku systemów SaaS podajemy adres uniwersalny dla wszystkich instancji tj. https://app.amage24.com/router/bimsync/auth
|
W środowisku Catenda Hub dodatkowo mamy możliwość wywołania pierwszej autoryzacji, usunięcia tej autoryzacji lub wyświetlenia informacji o aktualnym zautoryzowanym użytkowniku oraz wybrać projekt, do którego podłączymy się za pomocą przeglądarki CDE w danej instancji.
REST API i dostęp
System udostępnia REST API dla integracji zewnętrznych systemów z systemem AMAGE. Aby uzyskać dostęp do API należy wykorzystać mechanizm autoryzacji za pomocą wbudowanych w system kluczy API. Wygeneruj klucz API i aktywuj go w systemie.
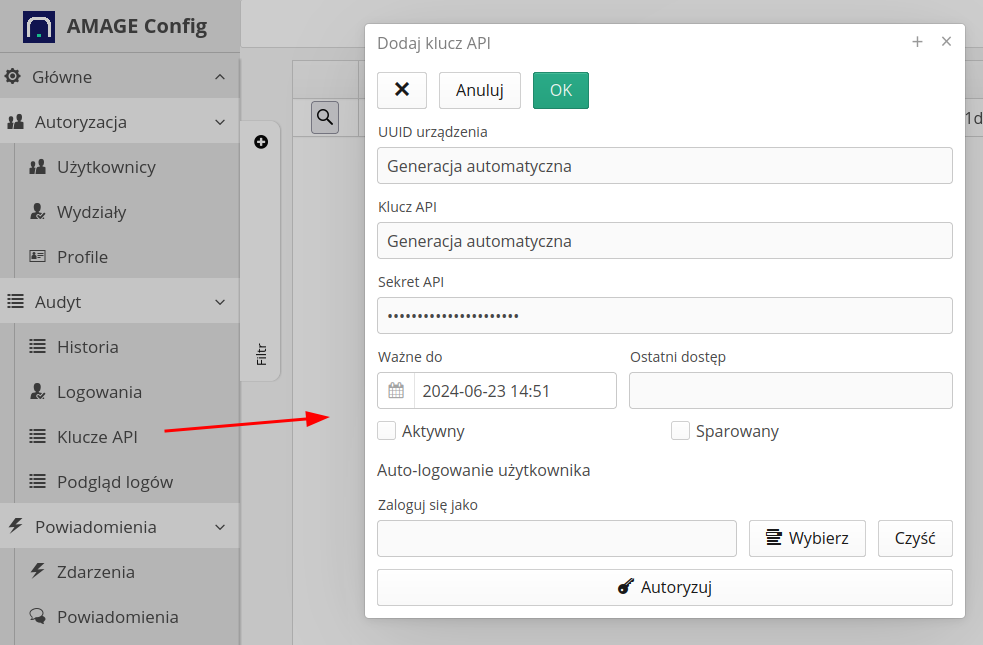
Zapisz informacje dotyczące identyfikatorów, klucza API oraz sekretu. Do autoryzacji zapytań REST API wykorzystaj te dane, aby wygenerować podpis zapytania i wysłać je w parametrach zapytania.
| Odnieś się do przykładów w Akademii AMAGE, aby zobaczyć mechanizm autoryzacji oraz zobaczyć przykładowe kody i zapytania, które służą do wykonania odpowiednich zapytań i komunikacji REST. |
Mechanizm REST udostępnia następujące interfejsy
REST API - udostępnienie danych raportów w formacie JSON
Raporty, które są dostępne w systemie AMAGE mogą być pobrane za pomocą REST API w formacie JSON. Format pozwala na pobranie danych i wykorzystanie ich w innych systemach typu Business Intelligence.
Interfejsy:
-
rest/amage/v1/reports/generate/json/by-bookmark-uuid/{uuid} - pobranie danych w formacie JSON generując dane przez bibliotekę Jasper. UUID jest unikalnym identyfikatorem zakładki raportu, z której generujemy dane.
-
rest/amage/v1/reports/generate/raw-json/by-bookmark-uuid/{uuid} - pobranie danych w formacie JSON generując bezpośrednio dane przez system AMAGE. UUID jest unikalnym identyfikatorem zakładki raportu, z której generujemy dane.
-
rest/amage/v1/reports/generate/raw-json/by-report-uuid/{uuid} - pobranie danych w formacie JSON generując dane bezpośrednio przez AMAGE. UUID jest identyfikatorem raportu. Dostarczane są wszystkie rekordy danego obiektu głównego, którego dotyczy raport.
Interfejsy oczekują dowolnego formatu zapytania i metody GET, zwracają format JSON ("application/json").
REST API - udostępnienie danych raportów w formacie PDF, XLSX
Interfejs pozwala na wygenerowanie raportów w formacie PDF/XLSX podobnie jak interfejs JSON.
Interfejsy:
-
rest/amage/v1/reports/generate/pdf/by-bookmark-uuid/{uuid} - wygenerowanie raportu PDF z zakładki o podanym UUID.
-
rest/amage/v1/reports/generate/xlsx/by-bookmark-uuid/{uuid} - wygenerowanie raportu XLSX z zakładki o podanym UUID.
Interfejsy oczekują dowolnego formatu zapytania i metody GET, zwracają format binarny ("application/octet-stream")
REST API - pobieranie załączników
Interfejs pozwala na pobranie załączników na podstawie ich UUID.
Interfejsy:
-
rest/amage/v1/attachment/get/by-uuid/{uuid} - pobranie załącznika (Attachment) o podanym UUID
Interfejsy oczekują dowolnego zapytania i metody GET, zwracają format binarny ("application/octet-stream") oraz nazwę oryginalną pliku.